DeepLearning -2 DropOut
Introduction and Problem of Overfitting
In deep learning, Overfitting is a common problem, in which model fits the training data very well, but perform worse in test data / unseen data. This is due to that when the model learns general features of the dataset, it also learns some specific features in some specific samples well. It makes generalization error increase as well.
Dropout is a regularization method that approximates training a large number of neural networks with different architectures in parallel. Or we can regard DropOut as a method of sampling sub-neural network within a full neural network by randomly selecting some neurons to feedforward and update weight.
How DropOut Work
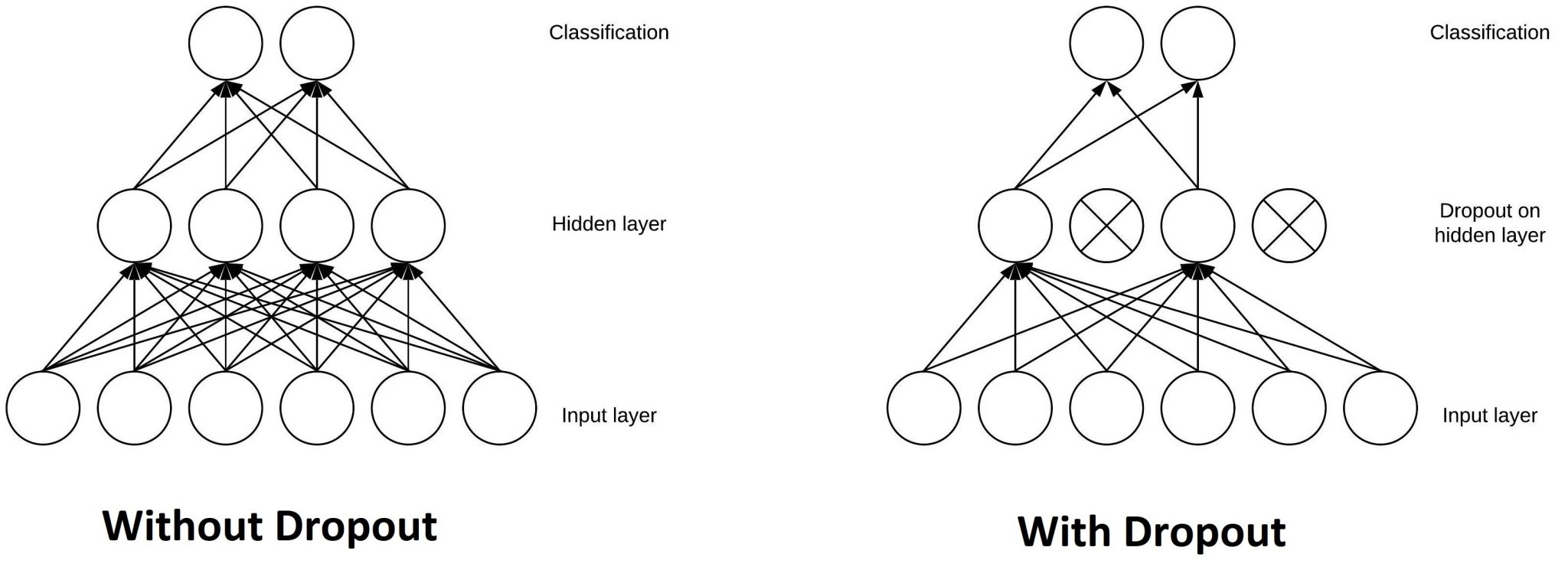
DropOut can be applied to any hidden layer. It is to randomly select some neurons in the hidden layer to output to the next layer. As the image shows here, in the second hidden layer, we randomly select some neurons to output and disable other neurons during feedforward process. Then in back propagation process, we only update the weights connected to those selected neurons. We can also regard DropOut as Sampling training technique in training weight.
In back propagation, since we randomly sample neurons to output, it can be regarded as a 0,1 mask to multiply the output in hidden layer. So in back propagation, the gradient to the weights of ignored neurons will be zeros.
Note that DropOut is applied in training step only. We DO NOT use dropout in prediction step as it can make the prediction unstable when randomly choosing different neurons for output.
DropOut Rate
DropOut rate is the possibility of training a given node in a hidden layer. If dropout rate is large, then it is more likely to select and train the node in hidden layer.
For example, if dropout rate = 0.1, then each node in a hidden layer has only 0.1 possibility of being trained (enabled to feedforward and back propagation) in training step. If dropout rate = 1, then all neurons in network will be trained.
Code of dropout
1 | def forward(X): |
Properties of DropOut
- dropout is one way to regularize neural network and avoid overfitting
- dropout is extremely effective and simple
- It can be applied to any hidden layer output
Reference
[1] https://machinelearningmastery.com dropout-for-regularizing-deep-neural-networks/
[2] https://blog.csdn.net/qq_28888837/article/details/84673884