ensemble-learning-Stacking
Introduction
Stacking集成算法可以理解为一个两层的集成,第一层含有多个基础分类器,把预测的结果(元特征)提供给第二层, 而第二层的分类 器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。
Stacking
而在Stacking里面, 在第一层的模型是通过K-fold Cross validation 形式进行训练和预测。 而Blending的思路相对于把K-fold Cross validation换成Hold-Out。
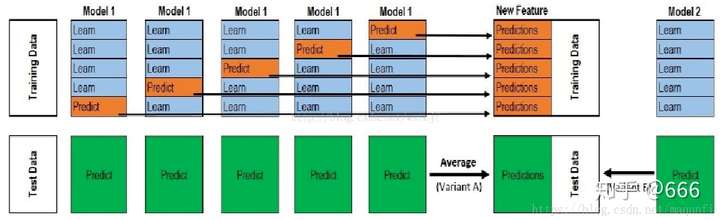
以下是Stacking 步骤:
(图片来源: https://zhuanlan.zhihu.com/p/91659366)
Stacking 的步骤是:
- 先把training set 的数据进行K-fold cross validation (sklearn 里面default 2fold) 每个模型都有K个fold的prediction。之后如果有多个不同的模型,就有多个K-fold的prediction。比如说如果我先把训练集分成 5fold,那么就是[X1, X2 … X5]. 如果我有两个不同的模型, 比如KNN和RandomForest那么对应的prediction分别是[A1, A2…A5], [B1, B2, … B5]。之后我们可以把对应序号的prediction进行average计算。 比如 [(A1+B1)/2, (A2+B2)/2 … (A5+B5)/2 ]。
- 之后把这些模型的输出作为第二层模型的输入。第二层模型一般是logistics regression,这个取决于具体任务
- 在test set里面, 用第一层的模型对test set的输出进行平均值计算得到第二层模型的测试集的输入,之后第二层模型预测输出。
Source Code
Github源码:
https://github.com/wenkangwei/Datawhale-Team-Learning/blob/main/Ensemble-Learning/Stacking.ipynb
Properties
Blending与Stacking对比, Blending的优点在于:
- 使用Cross validation 进行数据的预测作为第二层输入,能充分利用数据
- 相对于Blending,因为用了Cross validation不容易过拟合
缺点在于:
- 用 Cross validation 之后计算慢
Reference
[1] https://zhuanlan.zhihu.com/p/91659366
[2] https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning