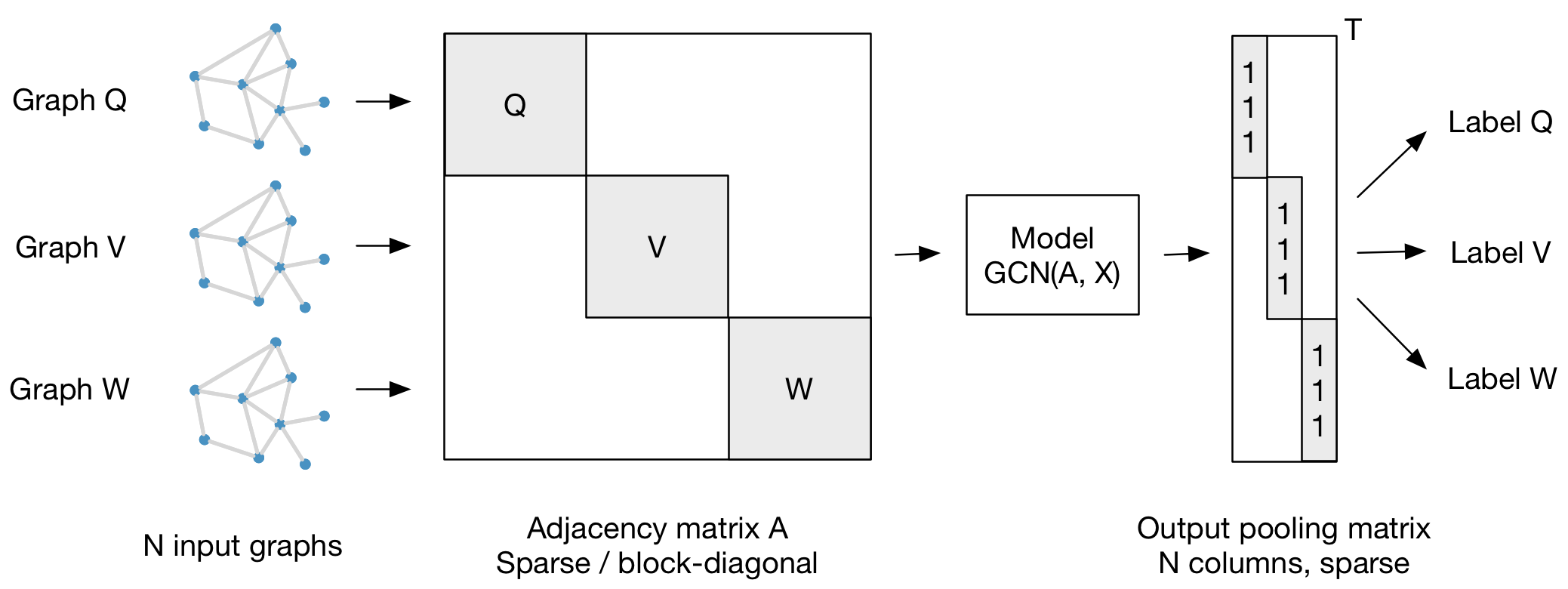
@property defraw_file_names(self): # list of file names of raw partial graphs return ['some_file_1', 'some_file_2', ...]
@property defprocessed_file_names(self): # list of file names of processed partial graphs return ['data_1.pt', 'data_2.pt', ...]
defdownload(self): # Download to `self.raw_dir`. path = download_url(url, self.raw_dir) ...
defprocess(self): i = 0 # process each raw file to get corresponding processed file for raw_path in self.raw_paths: # Read data from `raw_path`. data = Data(...)
if self.pre_filter isnotNoneandnot self.pre_filter(data): continue
if self.pre_transform isnotNone: data = self.pre_transform(data)
torch.save(data, osp.join(self.processed_dir, 'data_{}.pt'.format(i))) i += 1
WARNING:root:The number of nodes in your data object can only be inferred by its edge indices, and hence may result in unexpected batch-wise behavior, e.g., in case there exists isolated nodes. Please consider explicitly setting the number of nodes for this data object by assigning it to data.num_nodes.
WARNING:root:The number of nodes in your data object can only be inferred by its edge indices, and hence may result in unexpected batch-wise behavior, e.g., in case there exists isolated nodes. Please consider explicitly setting the number of nodes for this data object by assigning it to data.num_nodes.
WARNING:root:The number of nodes in your data object can only be inferred by its edge indices, and hence may result in unexpected batch-wise behavior, e.g., in case there exists isolated nodes. Please consider explicitly setting the number of nodes for this data object by assigning it to data.num_nodes.
WARNING:root:The number of nodes in your data object can only be inferred by its edge indices, and hence may result in unexpected batch-wise behavior, e.g., in case there exists isolated nodes. Please consider explicitly setting the number of nodes for this data object by assigning it to data.num_nodes.
Batch(batch=[6], edge_index=[2, 8], foo=[2, 16], ptr=[3])
import torch from torch import nn from torch_geometric.nn import global_add_pool, global_mean_pool, global_max_pool, GlobalAttention, Set2Set
import torch import torch.nn.functional as F
import torch from torch import nn from torch_geometric.nn import MessagePassing import torch.nn.functional as F from ogb.graphproppred.mol_encoder import AtomEncoder, BondEncoder
# computing input node embedding h_list = [self.atom_encoder(x)] # 先将类别型原子属性转化为原子表征 for layer in range(self.num_layers): h = self.convs[layer](h_list[layer], edge_index, edge_attr) h = self.batch_norms[layer](h) if layer == self.num_layers - 1: # remove relu for the last layer h = F.dropout(h, self.drop_ratio, training=self.training) else: h = F.dropout(F.relu(h), self.drop_ratio, training=self.training)
if self.residual: h += h_list[layer]
h_list.append(h)
# Different implementations of Jk-concat if self.JK == "last": node_representation = h_list[-1] elif self.JK == "sum": node_representation = 0 for layer in range(self.num_layers + 1): node_representation += h_list[layer]
return node_representation
classGINGraphPooling(nn.Module):
def__init__(self, num_tasks=1, num_layers=5, emb_dim=300, residual=False, drop_ratio=0, JK="last", graph_pooling="sum"): """GIN Graph Pooling Module Args: num_tasks (int, optional): number of labels to be predicted. Defaults to 1 (控制了图表征的维度,dimension of graph representation). num_layers (int, optional): number of GINConv layers. Defaults to 5. emb_dim (int, optional): dimension of node embedding. Defaults to 300. residual (bool, optional): adding residual connection or not. Defaults to False. drop_ratio (float, optional): dropout rate. Defaults to 0. JK (str, optional): 可选的值为"last"和"sum"。选"last",只取最后一层的结点的嵌入,选"sum"对各层的结点的嵌入求和。Defaults to "last". graph_pooling (str, optional): pooling method of node embedding. 可选的值为"sum","mean","max","attention"和"set2set"。 Defaults to "sum". Out: graph representation """ super(GINGraphPooling, self).__init__()
if self.training: return output else: # At inference time, relu is applied to output to ensure positivity # 因为预测目标的取值范围就在 (0, 50] 内 return torch.clamp(output, min=0, max=50)
6. Practice with GIN Regression Task using PCQM4M Dataset
import pandas as pd import torch from ogb.utils.mol import smiles2graph from ogb.utils.torch_util import replace_numpy_with_torchtensor from ogb.lsc import PCQM4MEvaluator from ogb.utils.url import download_url, extract_zip from rdkit import RDLogger from torch_geometric.data import Data, Dataset
import shutil
from tqdm import tqdm import torch from torch import nn from torch.utils.tensorboard import SummaryWriter from torchvision import datasets, transforms
x = torch.from_numpy(graph['node_feat']).to(torch.int64) edge_index = torch.from_numpy(graph['edge_index']).to(torch.int64) edge_attr = torch.from_numpy(graph['edge_feat']).to(torch.int64) y = torch.Tensor([homolumogap]) num_nodes = int(graph['num_nodes']) data = Data(x, edge_index, edge_attr, y, num_nodes=num_nodes) return data