XGBoost + LGBM
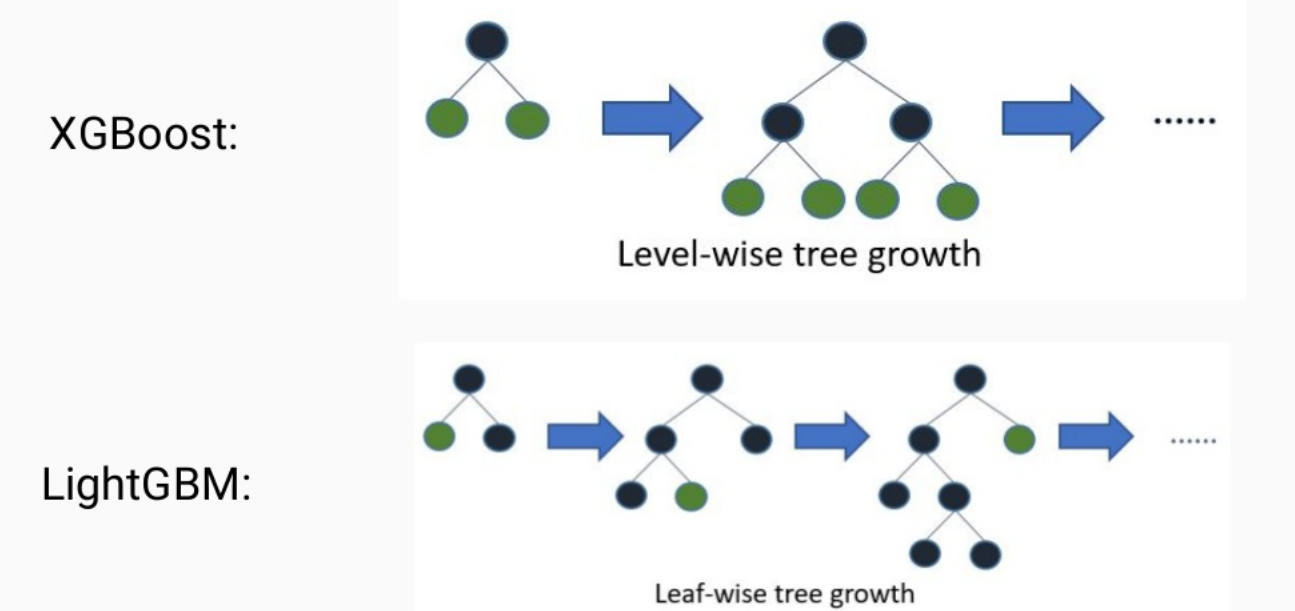
XGBoost + LGBM
GDBT介绍
GBDT——Gradient Boosting Decision Tree,又称Multiple Additive Regression Tree,后面这种叫法不常看到,但Regression Tree却揭示了GBDT的本质——GBDT中的树都是回归树。GBDT的主要是思想是每次把上一棵树的输出和label的残差作为下一棵树的label进行拟合,前面的树做不好的地方后面的补上,不断把拟合后的预测的残差值叠加上去,进行梯度的提升。具体步骤如下

其中负梯度相当于残差,用做target给下个tree进行拟合

GBDT的正则化防止过拟合的方法,主要有以下措施:
1,Early Stopping,本质是在某项指标达标后就停止训练(比如树的高度之类的),也就是设定了训练的轮数;
2,Shrinkage,其实就是学习率,具体做法是将每课树的效果进行缩减,比如说将每棵树的结果乘以0.1,也就是降低单棵树的决策权重,相信集体决策;
3,Subsampling,无放回抽样,具体含义是每轮训练随机使用部分训练样本,其实这里是借鉴了随机森林的思想;
4,Dropout,这个方法是论文里的方法,没有在SKLearn中看到实现,做法是每棵树拟合的不是之前全部树ensemble后的残差,而是随机挑选一些树的残差
XGBoost 介绍
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算 法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器 学习竞赛中并取得了不错的成绩。
XGBoost 原理
XGBoost的建树的步骤分为以下几步:
- 定义目标函数Objective function
- 通过泰勒展开式对Objective function进行简化
- 对简化后的Objective function进行求解得到树的每个leaf node输出的值的计算公式,以及对树结构的评估函数
- 根据所得到的评估函数用Exact Greedy algorithm 或者 近邻算法估计得到每个feature的分裂点以及对应的gain,并按照分裂点和gain对feature进行选取和分裂建树
XGBoost 推导
1. Objective function 优化目标函数:

在XGBoost的目标函数里面,它是基于GBDT的目标函数再加上一个 $\sum_i^t\Omega(f_i)$ 的对t棵树的输出regularization term正则化来抑制过拟合的问题. 而前面的loss 函数还是和之前一样 $y_i$ 是target $\bar{y_i}^{(t)}$ 是对前面t棵树的输出的线性相加的输出值。 在对第t棵树的输出进行计算时, 我们可以把第t棵树的regularization term和 预测值拆开来得到以上表达式。其中

而regularization term $\Omega(f_t) = \gamma T + \frac{1}{2}||w||^2$ 这里的gamm是一个penalty的系数而T是第t棵树 $f_t$ 的节点个数,w是这颗树的每个leaf node的输出预测。
2. 通过泰勒展示简化 Objective function 优化目标函数:
在XGBoost 里面,为了加速算法的计算,这里用了2阶的泰勒展开式对Objective function进行估计,泰勒展开式公式如下

之后我们可以把原来的目标函数简化成下面形式:

由于计算第t棵树的时候,前面t-1棵树的loss还有regularization的项是常数,我们可以不考虑。

把 $f_t(x_i)$ 树的输出替换成w的形式,我们得到关于w的一元二次函数

3. 通过对关于w的一元二次方程求解可得
由于我们的目标是要找出第t棵树使得我们当前的目标函数最小化,所以我们可以把上面的一元二次方程函数通过找极值的方法找到w的解以及对应的目标函数值,即 $x = - \frac{b}{2a}, y = \frac{4ac-b^2}{4a}$ 因此我们可以得到以下的解
$$
w_ j^* = - \frac{\sum_ {i\in I_ j} g_ i}{\sum_ {i\in I_ j} h_ i + \lambda}
$$
$$
OBj^{t}(q(x)) = -\frac{1}{2} \sum_ {j=1}^T\frac{(\sum_ {i\in I_ j} g_ i )^2}{\sum_ {i\in I_ j} h_ i + \lambda} + \gamma T
$$
这里的 $I_ j$ 是指属于第j个叶节点的样本的集合,wj 是第j个节点的输出值,而 $g_ i , h_ i$ 分别是关于之前t-1棵树的模型对第i个样本的输出的Loss的1阶和2阶的导数。 这里的目标函数 $OBj^t(q(x))$ 的值可以看成是对当前的第t棵树的loss,而q(x)代表了第t棵树的结构。
4. 根据前面的OBj score 的函数 对当前节点下的所有feature查找最大的gain,并根据概念找到每个feature的split 分裂点来建树
虽然计算第t棵树的每个leaf node的输出值的公式是有了, 但是我们其实还没有确定这棵树的结构。为了找到树的结构,我们需要给每个特征找到分裂点,以及在每一层对特征选取。而这里就需要用到第3步找到的leaf node 输出的值和目标函数值函数了。
这里举个例子, 在下图,假设我们先只考虑黄色看看的树。如果我们一开始还没建树,需要先选取一个feature (1个column)用来作为一个root node。那么为了使目标函数最小化我们最直接的方法是直接这个feature里面的出现的数值排序,然后把每两个值之间的间隙当成分裂点,然后看哪个分离点对应的 $OBj(q(x))$ 目标函数是最小就选那个作为当前的分裂点。所以这样在这个例子我们的分裂点是 x<=6 , x>6。这时我们的loss就是 $L^{old} = OBj(q(x))$ of old tree structure

由于我们想要通过添加剩下的feature作为tree的分支使得tree的loss 越小越好,那么对于old的框框下增加branch之后的tree的结构所对应的loss,标记为 $L^{new} = = OBj(q(x))$ of new tree structure。 我们就想要最大化 $$max(L^{old} - L^{new}) = OBj^{old} - OBj^{new}$$
而我们可以标记 $$L^{split} = max(L^{old} - L^{new})$$ 作为分裂增益, split gain。split gain公式可以变成

之后我们可以找到当前可以选的feature所对应的最大split gain以及对应的分裂点,并选取split gain最大的那个feature作为当前的tree node分支。 不断重复这几步就可以把树建起来了。
而这个每次都要线性扫描分裂点的建树的方法也叫做 Exact Greedy Algorithm。在当前的节点里面,把归到这个节点里面的样本做以下操作:

由于这个方法每次都要把feature的数值排序并线性扫描,在计算连续特征的时候还要先排序并把每两个值的中点作为分裂点候选点来离散化,这样计算会很慢并且会在大量数据时内存容易不足。在XGBoost里面用了一种 近似算法(Approximate algorithm)按照预定的百分位对数值进行分桶得到候选的分裂点集合,然后再用Exact Greedy algorithm 进行分裂点选取。以下是原paper的描述:

例子:

5. 对缺失值或稀疏值处理
在XGBoost 里面,它能够自动处理缺失值和稀疏值时是把它们放到稀疏矩阵里面处理
- 对于训练时遇到的缺失值默认把它们试着分别放到右子树,左子树然后找到最大的gain的分裂点进行分裂。并且计算时间只考虑非缺失值
- 对于预测时遇到的缺失值,默认被分到右子树。
- XGBoost把稀疏数据和缺失数据用相同方式处理。不过对类别特征还是要encoding成稀疏值后才能处理。

XGBoost 特点
GBDT:
- GBDT 它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
- GBDT 的缺点也很明显,Boosting 是一个串行过程,不好并行化,而且计算复杂度高,同时不太适合高维稀疏特征;
- 传统 GBDT 在优化时只用到一阶导数信息。
Xgboost 它有以下几个优良的特性:
- 显示的把树模型复杂度作为正则项加到优化目标中。
- 公式推导中用到了二阶导数,用了二阶泰勒展开。
- 实现了分裂点寻找近似算法。
- 利用了特征的稀疏性, 对计算加速,计算的时间只和非缺失值的个数线性相关
- xgboost在训练之前,预先对数据通过并行计算进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。
- 传统GBDT用了所有数据,但XGBoost像RandomForest一样用了Column Subsampling 来抑制overfitting并且加速了计算。
- 传统的GBDT没有设计对缺失值进行处理需要人工对缺失值处理,XGBoost能够自动学习出缺 失值的处理策略。
- 树模型对outlier不敏感,不像Parameterized model,如LR之类的
- XGBoost 相对于传统的GBDT可以处理缺失值,并且处理稀疏数据时比GBDT要好
- 思路总结: 加了Regularization term -> 用二阶泰勒展开式对树模型求解->得到每个叶子的输出计算公式以及对树结构的gain的计算方式->通过gain的计算方式+ 贪心算法找到每个feature的分裂点 ->按照分裂点的gain提出对稀疏值和缺失值的处理方法 ->
其他特点:
- GBDT 用的CART tree分类时用的是Gini gain 而回归时用方差 variance,而XGBoost里面的启发函数用的是一个基于前面树的梯度的一阶二阶导数的Loss
LGBM
LGBM 相对于是对XGBoost的工程上的优化
- LGBM 通过利用直方图分桶和采样的方式对XGBoost进行加速,计算速度远快于XGboost (用GOSS对样本采样, 用EFB对稀疏特征捆绑成新特征减少特征量)
- LGBM相对于XGboost需要更少的内存
- LGBM和XGBoost一样能够处理缺失值
- LGBM是不需要对类别特征进行onehot 编码处理,而XGboost需要onehot编码类别数据形成稀疏值后才能进行计算.
- 对于缺失值处理, XGBoost是把它当成稀疏值进行处理并且排序时把稀疏值放到左边或右边并排序来找最优分裂点,而LGBM是不需要输入数据编码,自动把特征编码并且通过EFB算法把多个稀疏值合并成更少特征。
LGBM对XGBoost有3个改进之处
在找分裂点时,LGBM用直方图方法进行采样

LGBM可以通过预先把特征值进行排序,找到分位数,并按照分位数把特征离散化得到多个bins,而不像XGBoost把每个分裂点都遍历一遍,从而提高计算速度
在样本采样中,用GOSS根据梯度大小对样本采样进行下一个模型更新
Gradient-based One side sampling 单边采样 (GOSS) 算法的创新之处在于它只对梯度绝对值较小的样本按照一定比例进行随机采样,而保留了梯度绝对值较大的样本。这个梯度的大小可以由阀值进行决定

在特征采样中,LGBM用EFB互斥特征绑定方法进行特征采样
EFB算法全称是Exclusive Feature Bundling。 EFB算法可以有效减少用于构建直方图的特征数量,从而降低计算复杂度,尤其是特征中包含大量稀疏特征的时候。在大量稀疏数据时相似ID数据,尽管用了之前的GOSS样本采样以及直方图找分裂点,但是太多稀疏特征依然会降低计算速度。
LGBM考虑多个稀疏的特征在很多情况下都是为0的,很少时候同时不为0,所以它假设这些特征是互斥的,因此可以把这些稀疏特征捆绑在一起作为一个新的特征。
对于指定为类别特征的特征,LightGBM可以直接将每个类别取值和一个bin关联,从而自动地处理它们,而无需预处理成onehot编码多此一举。
时间复杂度
XGBoost时间复杂度
- 对每个连续特征预排序O(nlogn), n = sample 个数
- 建树时 O(nxm), n= 样本的数目, m=特征的数目,因为要对每个特征的排序后的样本进行扫描找分裂点。
LGBM时间复杂度:
- 在分桶的时候,LGBM里面用了直方图统计的方法,没有用到预排序,不用考虑预排序时间复杂度
- 在GOSS单边采样的时候,它先把样本根据梯度大小排序,然后按照梯度来选取样本。(注意LGBM里面的排序是为了采样,XGBoost里面的排序是为了找分裂点)
- 在搭建直方图时, 由于要对每个feature进行分桶,并且把样本分到每个桶里,所以O(number of data x number of feature)。并且由于子节点的直方图的和是等于父节点的直方图,所以可以做差加速对直方图做快速计算,不用重新统计
- 找直方图分裂点时, O(number of bins x number of feature),因为要遍历每个桶进行最大增益分裂点的查找。

Reference
[1] 知乎 https://zhuanlan.zhihu.com/p/143009353
[2] 知乎 https://zhuanlan.zhihu.com/p/58269560
[3] 知乎 https://zhuanlan.zhihu.com/p/53980138
[4] XGBoost Paper: https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
[5] LGBM Paper: https://papers.nips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
[6] CSDN: https://blog.csdn.net/pearl8899/article/details/106159264
[7] Image: https://rohitgr7.github.io/content/images/2019/03/Screenshot-from-2019-03-27-23-09-47-1.png