Data-Analysis-1-Visualization
Introduction
这篇文章主要用于总结pandas, seaborn常用的可视化图表的操作,便于下次数据可视化时直接用。另外也总结一下可视化技巧,什么场景用什么图片对数据之间的关系进行分析。
这里先来介绍data visualization的目的
- 用于发现hidden pattern 一些隐藏的数据的特征趋势和关系
- 搭建或测试假设hypothesis。 有时通过观察数据会有对数据间的提出一些假想。这时需要我们对数据可视化看看有没有支持这个假设的特征趋势或分布
- 解释模型的输出结果,对预测结果可视化解释,分析模型性能
- 确定下一步建模怎么做,用什么特征去搭建。比如linear regression
Type of Visualization
数据可视化的分析基本上可以分为以下几种:
Distribution
对特征的数量,频率, 概率分布等进行可视化。 可以是单个或多个连续特征或者是离散(如category, ordinal)特征进行可视化。 (一般使用distplot, countplot, barplot, lineplot等)Relationship
观察两个或多个特征之间的关联, 比如年龄和身高的关系可以用lineplot, scatterplot等可视化Composition
将数据集根据variable 的值进行分组对比, 比如收入分布分析时按照gender进行男女分组Comparison
对比多个不同数据集或variables之间的趋势对比。 比如在过去一个星期的数据和这个星期的数据里面商品销量的变化趋势的对比
Visualization Methods
Plots
对应不同分析类型的可视化可以用不同的图
- Amount
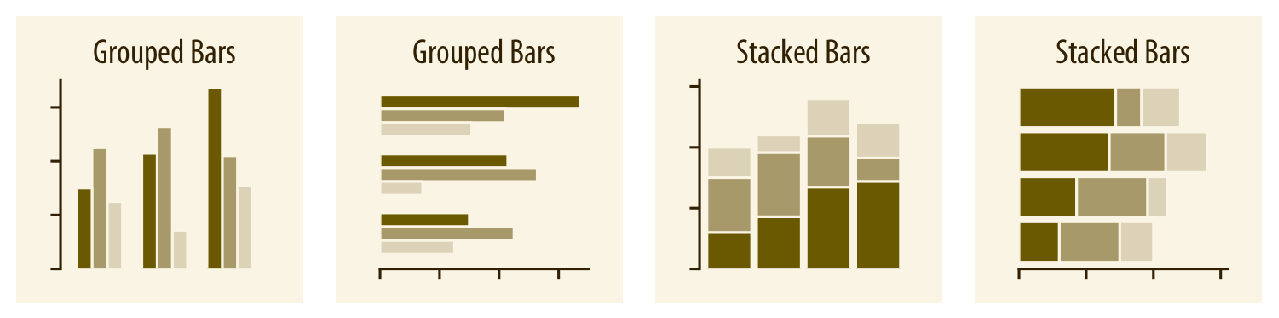
- Distribution
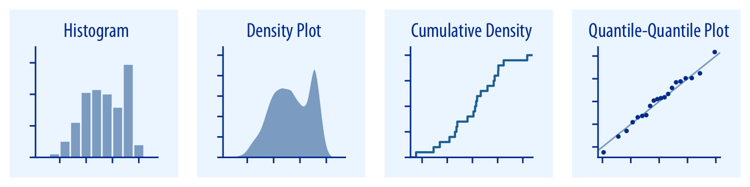
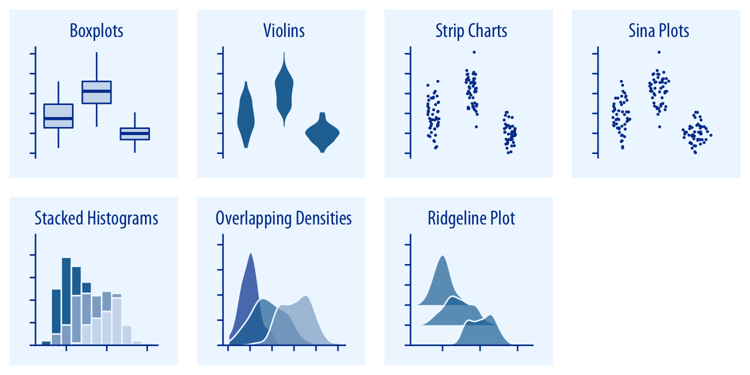
- Proportions
单个离散变量的各个值的比例
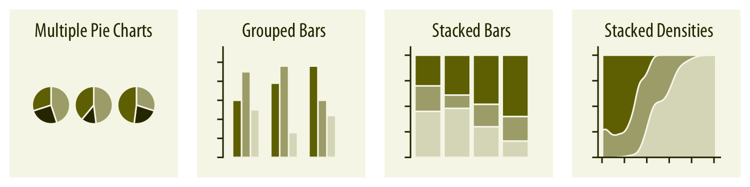
- Relations
两个或多个变量的关联性一般可以通过scatterplot, lineplot, 来分析变量之间的关系和倾向性
- Uncertainty
不确定性的可视化一般用 mean均值, variance方差统计量来统计和可视化。如果是根据离散变量或数据集对数据进行分组subgroups (x是category变量,y是连续变量), 一般可以通过Eyes plot或者violet plot进行variance, mean统计。
对于x-y都是连续变量的情况, 可以通过lineplot进行均值画线以及UIvariance的band带宽画出来
Seaborn plots
Tips for exploring hidden patterns
- 结合实际业务应用场景,考虑哪些特征可能有用或和目标预测特征关联性强,并提出假设
- 单个特征分布: 提取感兴趣的特征,并对特征的数量,频率,这个特征各个数值的占比等看单个变量的分布。用distplot,barplot,piechart等
- 特征分组下的分布: 根据某个特征分组看单个特征的分布。 比如性别分组, 推荐里面Topk热门商品和长尾商品分组, 类目分组等
- 特征之间的关联: 把这个特征和其他1到2个的特征关联和趋势分析,比如label,或者其他输入特征进行画图分析。连续-连续特征用lineplot, scatterplot等, 连续-离散特征可以用barplot,
- 构建新特征分析: 将这个特征和其他特征进行变换得到新特征, 再重复step2~3。 这里的新特征变换可以参考一下变换
- 变成率值: 可以像是把UV 访客量变成点击量(点击UV/ 曝光UV)
- 把多个category特征合并,比如是否多个作家,是否多个歌手可以合并成4种情况: 1个作家1个歌手,1个作家多个歌手,多个作家1个歌手,多个作家多个歌手
- 非线性变换: log变换, polynomial多项式变换
- 连续特征分桶离散化: 收入(1
100)可以分桶成多个离散值 (110, 1020, 2030 …) - 聚类分组: 用kmean,embedding等进行相似度计算然后分组得到新特征label
- embedding: word2vec,以及feature crossing交叉
- 目前商品推荐常用的特征有:
- 行为特征: 过去7/14/30天的(实时)加车率, (实时)点击率, (实时)曝光率, 以及对应的点击,加车商品列表
- 商品属性特征: 类目( 末端, 一,二级类目), 销量,价格,颜色,风格,
- 用户属性特征: 性别,体型,年龄,是否活跃用户