PySpark-Note-1

Introduction
This note is to introduce some useful functions in PySpark and also do some practice with them to analyze SF crime dataset. Then KMean Clustering model is applied to show how to use ML model in PySpark.
List of Useful Functions
Create Spark Session
SparkSession
Create spark session, the main entry to create DataFrame, register DataFrame as tables, execute SQL over tables, cache tables, and read parquet files.1
2
3
4
5
6from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local") \
.appName("Word Count") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()Explanation:
- .master(‘local’): sets the Spark master URL to connect to. “local” mean run spark locally. Just like a local server
- .appName(“Word Count”) : application name
- .config(“spark.some.config.option”, “some-value”): configure some key-value pair in application
- .getOrCreate(): Gets an existing SparkSession or, if there is no existing one, creates a new one
SQLContext
As of Spark 2.0, this is replaced by SparkSession. However, this class is kept here for backward compatibility.
A SQLContext can be used create DataFrame, register DataFrame as tables, execute SQL over tables, cache tables,and read parquet files.
Load data
After we create a SparkSession, we can use the following code to read data from CSV or JSON file.
Returned Object: PySpark DataFrame object- csv
1
2
3
4
5
6
7
8# Set delimiter = ";" between columns
# Skip header of file if header=True.
# Otherwise, load header as data record
spark.read.options(header= True,delimiter=";") \
.csv("path-to-dataset/dataset.csv")
# or
spark.read.options(header= True,delimiter=";") \
.format('csv').load("path-to-dataset/dataset.csv") - json
1
2
3spark.read.json("path-to-dataset/dataset.json")
#or
spark.read.format('json').load("path-to-dataset/dataset.json")
- csv
Useful functions of pyspark.sql.DataFrame with SQL
Create DataFrame and SQL table
df.createDataFrame(data, schema=None):
create PySpark dataframe
data: a list of tuples,each tuple contains the data of a row
schema: a list of column names of dataframe1
2
3
4
5spark = SparkSession.builder\
.master("local").appName("Word Count")\
.config("spark.some.config.option", "some-value").getOrCreate()
l1 = [('Alice', 1)]
new_row1 = spark.createDataFrame(l1,["name","age"])df.createGlobalTempView(view_name)
Creates a global temporary view with this DataFrame.df.createOrReplaceTempView(view_name):
Creates or replaces a local temporary view with this DataFrame.df.registerDataFrameAsTable(table_name):
Registers the given DataFrame as a temporary table in the catalog.
Show Columns, Rows, Statistic description
df.columns: a list of column names
df.summary(): Computes specified statistics for numeric and string columns, with count - mean - stddev - min - max.
df.describe(): Computes basic statistics for numeric and string columns. Similar to summary()
df.printSchema(): print Schema / decriptions of each column, like data type
Query and Selection
df.head(10): return the top 10 rows in Row type, not DataFrame
df.tail(10):return the last 10 rows in Row type, not DataFrame
df.where(condition) or df.filter(condition) : select the rows which satisfy the conditions. Return a DataFrame
1
2
3
4
5
6
7
8# Select ages that are < 100 and City name = "SF"
# Using SQL expression in conditions
df.where("age < 100 and city in ('SF') ")
#Using Spark API
from pyspark.sql import Row
from pyspark.sql.functions import col
df.where(col("age")<100 & col('city').isin(["SF"]))df.column.isin([‘a’,’b’])
Check if the value in a column is in the list or notdf.column.between(lower_bound, upper_bound)
check if the value is within a range or notdf.select([“column-name”]):
select the columns based on a list of given column-namesdf.take(N):
Return a list the top N rows in Row() formatdf.collect():
convert pyspark dataframe to a list of row in Row() format
Handle data
- df.withColumn(‘column_name’, col):
append a column to dataframe with name “column_name”
col: a Column expression for the new column. we can use UDF (user defined function) to it as well.
1
df = df.withColumn("age", df.age+2)
df.withColumnRenamed(“old name”,”new name”):
rename a column in the dataframedf.drop([“column-name”]), df.dropna(subset =[“column-name”])):
drop columns and drop the rows with NaN in selected columnsdf.dropDuplicates([“column-name-to-remove-duplicated-value”]):
drop duplicated rows in selected coumnsdf.fillna(), df.fill_duplicates(): fill na with given values
df.spark.sql.Row(age=10, name=’A’):
Return a row with elements: age=10, name=’A’df.orderBy([“column-name”], ascending=False), df.sortBy():
orderBy is an alias of sortBy, they sort the dataframe along given column namesdf.groupby().agg() / df.groupby().count()
Apply aggregation function, such as count() to a group1
2
3# First select group based on column A, B. Then count the amount of group "A"
from pyspark.sql import functions as F
df.groupby(["A"]).agg(F.count(df.A))
- df.withColumn(‘column_name’, col):
Append New Rows
df.union():
Return a new DataFrame containing union of rows in this and another DataFrame, based on position.df.unionByName([“colunm-name”])
The difference between this function and union() is that this function resolves columns by name (not by position)1
2new_row = spark.createDataFrame([("A",1)],["name","count"])
df = df.union()
SQL
- df = SparkSession.sql(“select * from table”)
Display Data
- df.show(n)
Data Types Convertion with Pandas
df.toPandas()
convert dataframe to pandas dataframedf.toDF()
convert a list of Rows to PySpark dataframeConvert Pandas DataFrame to PySpark DataFrame using Schema
1
2
3
4
5from pyspark.sql.types import *
mySchema = StructType([ StructField("col name1", IntegerType(), True)\
,StructField("col name2", StringType(), True)\
,StructField("col name3", IntegerType(), True)])
spark_df = spark.createDataFrame(df, mySchema)
- Using Resilient distributed Dataset (RDD)
RDD represents an immutable, partitioned collection of elements that can be operated on in parallel.
Please refer to the official website about RDD
Practice with Example: SF Crime data
Requirements:
- Find a platform for distributed computing, like databricks
- Install PySpark
Download SF Crime Data for Demo
1
2
3
4
5import requests
r = requests.get("https://data.sfgov.org/api/views/tmnf-yvry/rows.csv?accessType=DOWNLOAD")
with open("sf_crime.csv","w") as f
f.write(r.content)
f.close()Load Data with PySpark
1 | from pyspark.sql import SparkSession |
Visualize Data
1
2
3
4
5
6
7
8
9
10
11# Create a view called "sf_crime" to the dataframe, so that we can use SQL
# to query data later
df_opt1.createOrReplaceTempView('sf_crime')
# if using databricks, we can use display function to see the data
display(df_opt1 )
# or
df_opt1.show()
# or
# show the schema of dataframe
df_opt1.printSchema()Clean Data
Change the string data type to date type, integer type and other suitable data type
1 | # convert data type and replace data |
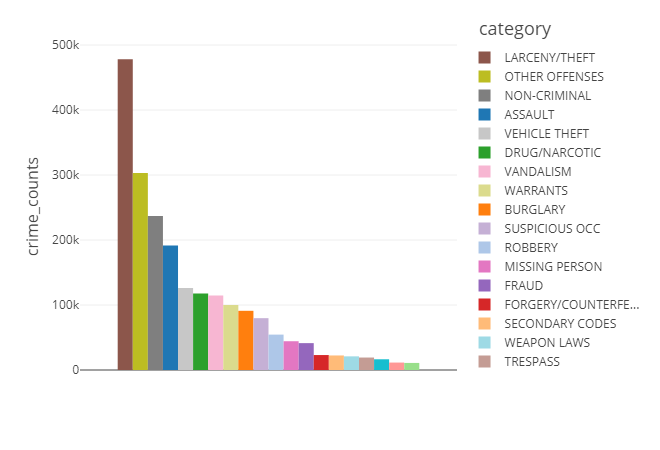
- Query and Select data I’m interested in
I want to analyze the count of crime of each category here, so there are two ways to do this.
1 | # Display Count of cime using SQL |
Result
Advance Topic: Machine Learning Model
Using KMean Clustering to find the 5 centers in which crimes occur frequently
- Select Position data X,Y and then Use Interquantile Range method to find outliers of position
Since KMean Clustering is sensitive to the outlier as it uses mean method to find the center of clusters, we need to remove outliers first.
- Quantile Based method to remove outlier:
The outlier is defined as the data point that drop outside the range [Q1-1.5IQR , Q3+1.5IQR],
where Q1 and Q3 are the first and third quantile of dataset and IQR = Q3-Q1 is the interquantile range.
- API in PySpark to find quantile:
df.approxQuantile(col, probabilities, relativeError):
col: column to find quantile
probabilities: a list of quantile probabilities we want to find. Here I want to find Q1 =0.25 and Q3=0.75
return: the a list values that correspond to the quantile in probabilities list.
1 | # select the positions where crimes occur |
Remove Outliers based on upper bound and lower bound of quantile
1
2
3
4from pyspark.sql.functions import *
crime_cluster_df = crime_cluster_df.select(["X","Y"])\
.where(col("X").between(bounds['X']['lower'], bounds['X']['upper'])) \
.where(col("Y").between(bounds['Y']['lower'], bounds['Y']['upper']))
Assemble columns into one feature column before training
In PySpark, we need to put all feature columns into one single feature column before we train the model.
VectorAssembler provides a way to assemble those features into one column.
1 | # ensemble multiple columns into one single feature column for training KMean Clustering |
- KMean Clustering to learn data
In Machine Learning of PySpark, we need to set the name of feature column to “features”, otherwise, setfeaturesCol="column-name"to select which feature column to learn in dataframe
1 | # Training KMean clustering |
Result


Summary
This tutorial introduce:
- List of useful PySpark functions and their basic usage
- Use SF Crime dataset as a demo to see how to use PySpark to manipulate data and visualize them
- How to use machine learning model: KMean Clustering in PySpark to learn data. Note: the APIs of ML in PySpark are different from sklearn. Need to Pay attention to the difference.
Reference
[1] SparkReader,Writer
[2] PySpark,SQL_module
[3] PySpark,ML_module
[4] PySpark,outlier_detection
[5] logo