CPSC 6300 Final Report

TITLE: KKBox Music Recommendation System
Team Members: Wenkang Wei, ShuLe Zhu
Date: 12/5/2020
Problem Statement and Motivation
Problem statement
As the public is listening to all kinds of music and there is a diversity of the favors of different individuals in listening music, music users may choose different music platforms based on which platform can provide the kinds of music closest to their tastes. In order to help music platforms figure out how to recommend suitable kinds of music and songs to individuals or groups so that they can provide better services and retain users, it is necessary to analyze the tastes of individuals and the public in listening to music and explore the chances that users may repeat listening some songs based on data analysis.
In addition, users, who listen to a large number of songs and add many songs to their favorite albums, usually forget what songs they have collected and which songs they like when trying to re-play those songs. In this case, it is necessary to build a recommendation system to help us predict the songs users may repeat listening to after the user’s a very first observable listening event.
Motivation and Goal
We are to construct a recommendation system to predict the chances of a user listening to a song repetitively after the first observable listening event within a time window was triggered. If there are recurring listening event(s) triggered within a month after the user’s very first observable listening event, its target is marked 1, and 0 otherwise in the training set. By constructing such a recommendation system, we are able to remind music users of their favorite songs and increase the rate of the audience as well as the benefit to the music platform.
Introduction and Description of Data
Music is important in our daily life and the role of music is determined by people and the environment. Music has a lot of help, for example, it can cultivate sentiment and reduce stress. However, some people don’t need music in their lives or live in music. People who never listen to music or harmony feel that music has a low sense of existence. But in fact, in their everyday lives, they actually have songs, ringing alarms, wind, and rain. So, the role of music performance is one of the most important companions in life.
In order to recommend suitable music to users in music platforms efficiently, a recommendation system is an essential part of music platforms. A recommendation system is a subclass of an information filtering system that seeks to predict the “rating” or “preference” a user would give to an item. Due to the fact that there are millions of kinds of music, composers, artists, and other information from users, it is hard for users to pick the kinds of music they like from millions of songs and remember which songs they like and want to re-play. Usually, users forget the songs they have added to their favorite song album due to the large number of songs they have a play. Hence it is necessary to build a music recommendation system to recommend kinds of music, which users prefer and are likely to repeat listening to.
The dataset we collected is KKBox Music 1.7GB dataset. Our dataset is from Kaggle KKBox-Music-Recommendation-Challenge. You can also get the dataset from our GoogleDrive . The description of the dataset is as follow:
Descriptions of dataset:
train.csv
- msno: user id
- song_id: song id
- source_system_tab: the name of the tab where the event was triggered. System tabs are used to categorize KKBOX mobile apps functions. For example, tab my library contains functions to manipulate the local storage, and tab search contains functions relating to search.
- source_screen_name: name of the layout a user sees.
- source_type: an entry point a user first plays music on mobile apps. An entry point could be album, online-playlist, song .. etc.
- target: this is the target variable. target=1 means there are recurring listening event(s) triggered within a month after the user’s very first observable listening event, target=0 otherwise .
test.csv
- id: row id (will be used for submission)
- msno: user id
- song_id: song id
- source_system_tab: the name of the tab where the event was triggered. System tabs are used to categorize KKBOX mobile apps functions. For example, tab my library contains functions to manipulate the local storage, and tab search contains functions relating to search.
- source_screen_name: name of the layout a user sees.
- source_type: an entry point a user first plays music on mobile apps. An entry point could be album, online-playlist, song .. etc.
sample_submission.csv
- sample submission file in the format that we expect you to submit
- id: same as id in test.csv
- target: this is the target variable. target=1 means there are recurring listening event(s) triggered within a month after the user’s very first observable listening event, target=0 otherwise .
songs.csv
The songs. Note that data is in unicode.- song_id
- song_length: in ms
- genre_ids: genre category. Some songs have multiple genres and they are separated by |
- artist_name
- composer
- lyricist
- language
members.csv
user information.- msno
- city
- bd: age. Note: this column has outlier values, please use your judgement.
- gender
- registered_via: registration method
- registration_init_time: format %Y%m%d
- expiration_date: format %Y%m%d
song_extra_info.csv
- song_id
- song name - the name of the song.
- isrc - International Standard Recording Code, theoretically can be used as an identity of a song. However, what worth to note is, ISRCs generated from providers have not been officially verified; therefore the information in ISRC, such as country code and reference year, can be misleading/incorrect. Multiple songs could share one ISRC since a single recording could be re-published several times.
In preliminary EDA, we take a look to the features in different data files.
1 | train_df.info() |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7377418 entries, 0 to 7377417
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 msno object
1 song_id object
2 source_system_tab object
3 source_screen_name object
4 source_type object
5 target int64
dtypes: int64(1), object(5)
memory usage: 337.7+ MB
1 | test_df.info() |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2556790 entries, 0 to 2556789
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 id int64
1 msno object
2 song_id object
3 source_system_tab object
4 source_screen_name object
5 source_type object
dtypes: int64(1), object(5)
memory usage: 117.0+ MB
1 | song_df.info() |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2296320 entries, 0 to 2296319
Data columns (total 7 columns):
# Column Dtype
--- ------ -----
0 song_id object
1 song_length int64
2 genre_ids object
3 artist_name object
4 composer object
5 lyricist object
6 language float64
dtypes: float64(1), int64(1), object(5)
memory usage: 122.6+ MB
1 | members_df.info() |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 34403 entries, 0 to 34402
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 msno 34403 non-null object
1 city 34403 non-null int64
2 bd 34403 non-null int64
3 gender 14501 non-null object
4 registered_via 34403 non-null int64
5 registration_init_time 34403 non-null int64
6 expiration_date 34403 non-null int64
dtypes: int64(5), object(2)
memory usage: 1.8+ MB
In the dataset description above, we can obtain the information from both sources of songs, songs, and members. By using the information of sources of songs, we can know where the songs re-played by users are from. The information about songs and members can provide us with details about what kinds of songs are often re-played by users, or what types of members are more likely to repeat playing songs. Such kinds of data can give us insight into users’ behaviors of repeating listening to music.
Based on the information from members, songs and sources of songs, we can use them as the input features to machine learning model. The target is the chance of a user listening to a song repetitively after the first observable listening event within a time window was triggered. If there are recurring listening event(s) triggered within a month after the user’s very first observable listening event, its target is marked 1, and 0 otherwise in the training set. Hence, the question can be defined as a binary classification problem and the prediction from machine learning model should be either possibility of the chance, or 0 , 1 binary value indicating if there is a chance.
Literature Review/Related Work
As for the KKBox music recommendation system project, many Kaggle users choose to use a light gradient boosting machine (LGBM) due to its simplicity in preprocessing a large amount of data, and its fast computation speed. Based on the blog [5], the LGBM model is a light gradient boosting machine model, which is based on multiple decision tree models and use gradient boosting ensemble learning method to improve the training accuracy. One work from Kaggle we refer to [3] is to use the LGBM boosting machine as a baseline to fit the dataset and train the model using binary cross-entropy loss since the prediction task in this project is a binary classification task.
In addition to the LGBM model, there are some deep learning models used for the recommendation system. One of the neural network models is called the wide and deep model [1] . In this model, first uses an embedding network to transform the sparse categorical data into dense numerical data in one branch. Then it merges the branch of categorical data and the branch of numerical features together to feed the traditional network in the main branch. The main branch of the neural network works as a classifier while the embedding neural network works as a transformation network to preprocess the data. Since in this Kaggle project, no one tries such a neural network model for this task, we are interested in trying this model and see how it works in this problem. Then we compare it with the LGBM models.
Modeling Approach
Task - Since this project is to predict the chances of a user listening to a song repetitively after the first observable listening event within a time window was triggered, the output from the machine learning model is the possibility that a user will repeat listening to a song after the first listening event. Hence, this problem can be modeled as a binary classification problem
Loss Function - Since this task is a binary classification problem, we simply select binary cross-entropy loss as the loss function used to train parametric machine learning models, like deep learning models, logistic regression, etc.
Evaluation Metric - The evaluation metric to measure the performance of the machine learning model is selected to be accuracy and AUC (area under the curve) since we care about how accurate the models could be.
LGBM Modeling - Light Gradient Boosting Machine (LGBM) model is a tree-based model,this model merge and train multiple decision tree models to do classification or regression tasks, using the Boosting ensemble learning process. It will automatically encode categorical data into vectors and train models for labels or one-hot encoding. Since it provides a fast way to transform categorical data and train models with good accuracy performance based on the results from leaderboard in Kaggle, we try it here and tune its parameters to fit the data.
Here is the reference to use LGBM: https://lightgbm.readthedocs.io/en/latest/Quick-Start.html
Wide and Deep Neural Network model - This model using the embedding network in the neural network, this model converts categorical attributes into dense vectors, allowing one to reduce the dimension of categorical data and remove key features such as PCA. Then for feature selection and classification in the main branch, it blends dense embedded vectors with numerical data. The main branch is a typical neural network that acts as a classification function using linear layers, activation functions (relu, softmax, sigmoid). The output is the possibility that the user may repeat listening to the music.
The architecture of Wide and Deep Model is referred to https://github.com/zenwan/Wide-and-Deep-PyTorch
Baseline model - We choose our baseline model as LGBM boosting machine model with following setings: ‘objective’: ‘binary’, learning_rate = 0.3 , num_leaves = 110, bagging_fraction = 0.95, bagging_freq = 1, bagging_seed = 1, feature_fraction =0.9, feature_fraction_seed =1, max_bin = 256, max_depth = 10, num_rounds = 200.
After we choose the baseline model, we tune the LGBM model by changing the max_depth parameter to be [10 , 15, 20 , 25, 30] to see how the depth affects our LGBM performance. After that, we also implement the Wide and Deep Model with learning rate = 0.001, binary cross-entropy loss, and 2 epochs. The reason why we use different settings on the Wide and Deep model is that the training process of the neural network is very slow and the convergence speed of the model is slower than the LGBM model. The training loss of the neural network is easy to increase after decreasing for some iterations. So we need to tune some parameters to train the neural network model.
Project Trajectory, Results, and Interpretation
Our goal in this project doesn’t change. It is to construct a recommendation system to predict the chances of a user listening to a song repetitively after the first observable listening event within a time window was triggered. If there are recurring listening event(s) triggered within a month after the user’s very first observable listening event, its target is marked 1, and 0 otherwise in the training set.
Only one thing we change is that we choose to use neural network model and light gradient boosting machine (LGBM) model for this project, rather than using traditional models like KNN, logistic regression,
Here is the trajectory of our project
Timeline
| Date | Assignment | Wenkang | Shule |
|---|---|---|---|
| Oct 22 | Proposal | ✓ | ✓ |
| week 1 | Set up environment and Exploratory Data Analysis (EDA) | ✓ | ✓ |
| week 2 | Data preprocessing | ✓ | |
| week 3 | Modeling | ✓ | |
| Nov 12 | Interim Report | ✓ | ✓ |
| week 4 | Training model and Evaluation | ✓ | |
| week 5 | Training model and Evaluation | ✓ | |
| week 6 | Wrap up and preparing website presentation | ✓ | ✓ |
| week 7 | Writting Final Report | ✓ | ✓ |
| Dec 10 | Website and Final Report | ✓ | ✓ |
| Dec 13 | Notebooks and other supporting materials | ✓ | ✓ |
In this project, we follow these steps to build our data pipeline and recommendation system model:
First, in the exploratory data analysis step, we use visualization techniques to visualize and plot the features from the dataset to explore the correlation across features and find which features are most related to the target.
Here are partial results from EDA section
Genre Counts
Artist Count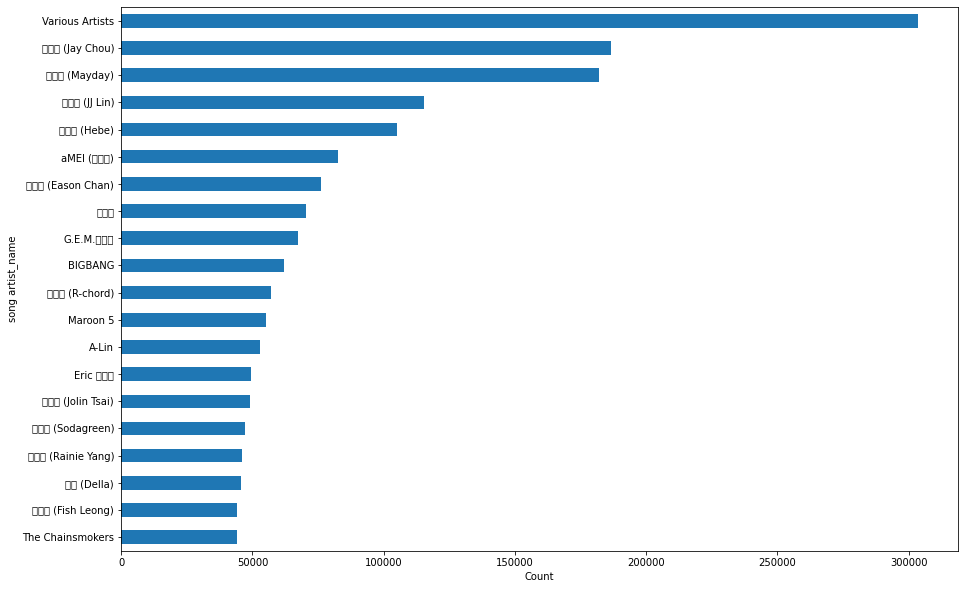
Count of system tabs, screen names, source types
In the Exploratory Data Analysis (EDA) part, we first analyze Song information by plotting and visualizing the counts of song genres, composers, artists, and the counts of source types, source screen names, system tabs. In this part, we find that the distributions of the counts of song genres, composers, artists are long-tailed distribution. That is, most users prefer listening to specific genres of music or songs created by specific artists, composers. In this case, we can know that those specific genres of music or songs from specific composers, artists are more likely to be re-played by users. In addition, when visualizing the counts of users vs source screen names, system tabs, and source types, we find that most users are more likely to repeat listening to music from their local sources, local library, rather than from online sources. That is, the features like source types, screen names, and system tabs provide important information for our recommendation system. Hence we choose to keep such kinds of features for modeling later.
Later, we analyze Member information, like visualizing the count of bd/age attribute and analyzing the correlation between different attributes using the heatmap plot. In this part, we find that there are many outliers in bd/age features with values outside the range of [0, 100]. After we remove such kind of outliers, we find that most users have ages between 20 to 40. After this, we try to plot bivariate plots to visualize and analyze the relationship between attributes, like city and age/bd, expiration date, and target. what we find is that registration_init_year is negatively correlative to bd/age, city, registered_via. Song_length is also negatively correlative to language.
In order to find which features are most related to targets, we plot the correlation matrix using a heatmap to visualize the correlation across features. In this part, since we find almost all other features have similar correlation values to the target, we choose to keep those features for modeling.
Then in data preprocessing, we clean and transform the features to a suitable format, like converting String DateTime data to DateTime format and separate year, month, day as new features, removing the outliers in bd/age features, filling missing values, creating new features like count of composers, artist, genres and converting object data type to categorical data type before training model
Later, we also construct a data pipeline to extract, transform, load data set by integrating the operations in the data preprocessing step into one single transformation function, which enable us to easily clean and transform dataset directly. After the data preprocessing and transformation step, we split the dataset into a training set (80% of the dataset) and a validation set (20% of the dataset) for training and validating our models. We also determine the Loss function (binary cross-entropy), evaluation metric (accuracy and AUC) to train our Light Gradient Boosting machines (LGBM) models and Wide and Deep Neural network model. During training our LGBM models, we are interested in how the max_depth affect the model performance, so we also try different max_depth parameters to tune our LGBM models.
In the Model evaluation step, we simply use the validation dataset to validate the final trained models and then let models make predictions on the test set from Kaggle and submit predictions to Kaggle to see the final evaluation scores.
Accuracy Results on our validation on LGBM model to see effect of max_depth on accuracy
| Index | Lgbm with max_depth | Validation Accuracy |
|---|---|---|
| 0 | 10 | 0.709764 |
| 1 | 15 | 0.719106 |
| 2 | 20 | 0.723689 |
| 3 | 25 | 0.725822 |
| 4 | 30 | 0.728842 |
We can observe that as the value of max_depth of the decision tree in the Boosting machine increases, both validation accuracy, and test accuracy increase gradually. It implies that the performance of our LGBM models may be improved by increasing the max_depth. As increasing max_depth can improve the learning/fitting ability of the LGBM model, it is possible that tuning other parameters like the number of leaves, the number of training epochs may also help improve the accuracy and let models better fit the dataset.
Accuracy Results on Kaggle Testset
| Model name | private score | public score |
|---|---|---|
| LGBM Boosting Machine Model 4 | 0.67423 | 0.67256 |
| LGBM Boosting Machine Model 3 | 0.67435 | 0.67241 |
| LGBM Boosting Machine Model 2 | 0.67416 | 0.67208 |
| LGBM Boosting Machine Model 1 | 0.67416 | 0.67188 |
| LGBM Boosting Machine Model 0 | 0.67206 | 0.66940 |
| Wide and Deep model | 0.61628 | 0.61117 |
Best Accuracy Results on Kaggle Testset from Kaggle Leaderboard
| Ranking | name | Score | Entries |
|---|---|---|---|
| 1 | Bing Bai | 0.74787 | 263 |
In the final results on test data from Kaggle, we can see that light gradient boosting machines have the accuracy performance better than the Wide and Deep Neural Network model. The best score in LGBM models is 67.256% while the Wide and Deep model has an accuracy of 61.11%.
Although the Wide and Deep model performance is not so well, we may improve its performance by tunning the parameters like dropout rate in the neural network, learning rate, training epochs in the future. In addition, in our experiments we try two epochs only, this is because we run the program in Google Colab and also try it in the Kaggle platform, but the hardware is not powerful enough to train the model quickly and there is a time limit in using GPU. Therefore, we can try better hardware to boost the training process in the future. What’s more, the best testing score from the Kaggle leaderboard is only 74.7887%, which means that this project is still challenging. It could be due to the difficulty in parsing and transforming the dataset to extract more meaningful patterns. The limitations of designing and training good models are also some factors since we don’t have enough computation power to train a large model, like Google, OpenAI. Overall, our works explore the effect of max_depth on LGBM models’ performance and also compare the performance of the Wide and Deep model with the performance of the LGBM model.
Conclusions and Future Work
In this project, there are still a few things that perform not very well. One obvious thing is the performance of the Wide and Deep model. We can easily see that the performance from the neural network model is low. This could be due to the small training epochs we use., as we use only 2 epochs to train the model using limited computation resources (Google colab). What’s more, we can also try different neural network architecture to better fit the dataset, or tune the parameters like learning rate, weight decay in the network to increase the learning ability of our network. As for the LGBM model, it seems like the LGBM model can better fit the dataset when using more training epochs and a larger max_depth value. We can also try to tune other parameters like the number of leaves, etc.
Overall, in the future, we may do the followings to improve our project:
In this project, there are several things we can improve in the future:
- We can use a better hardware platform for training models, rather than using Google Colab or Kaggle platform, so that we can better train the deep learning model.
- Tune the LGBM models using a grid search and choose larger max_depth values or tune other parameters
- Try to create more new features from text attributes like composer, lyricist, artist and use feature importance methods to pick features that most contribute to the prediction
In conclusion, we collect a 1.7GB KKBOX music dataset from Kaggle and do exploratory data analysis (EDA) on the data by visualizing the attributes and compute the correlations among features. Then we clean the dataset by removing outliers from age/bd attributes, filling missing categorical data with new labels, and missing numerical data with median value. We also transform the text data and create new features. After that, we use 80% dataset as training set and 20% dataset as a validation set.
In Modeling and Evaluation, we use LGBM models and Wide & Deep Neural network models to fit the dataset and also tune the max_depth parameter in LGBM to do binary classification tasks. The best accuracy performance of our models is 67.25% while the best accuracy from the Kaggle leaderboard is about 74%. In the end, we also summarize the future works to improve the project, like using better hardware resources, tunning other parameters of models, and explore more useful features for training.
References
[1] https://github.com/zenwan/Wide-and-Deep-PyTorch/blob/master/wide_deep/torch_model.py
[2] https://www.kaggle.com/c/kkbox-music-recommendation-challenge/submit
[3] https://www.kaggle.com/asmitavikas/feature-engineered-0-68310
[4] https://blog.statsbot.co/recommendation-system-algorithms-ba67f39ac9a3
[7] https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Dataset.html#lightgbm.Dataset
Support Materials
Dataset:
You can find the dataset from Kaggle: https://www.kaggle.com/c/kkbox-music-recommendation-challenge/data Or you can get the dataset from our Google Drive: https://drive.google.com/file/d/1-WJHZUWFtz9ksfvFoX-dc-ZKjZ6fTk0D/view?usp=sharingLink to Our website/ notebook in databrick platform:
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/3546981394788271/3905787926422076/7844345949955417/latest.htmlLink to Our notebook in Google Colab (This notebook is as same as notebook in databrick, but in Colab, you can directly run it after copying it to your drive):
https://colab.research.google.com/drive/1dssuTVKvDXM0zULihRt4tJUoOUoCxaFj?usp=sharingGithub repository of this project:
https://github.com/wenkangwei/cpsc6300-final-project
Declaration of academic integrity and responsibility
In your report, you should include a declaration of academic integrity as follows:
1 | With my signature, I certify on my honor that: |
1 | With my signature, I certify on my honor that: |
Credit
The above project template is based on a template developed by Harvard IACS CS109 staff (see https://github.com/Harvard-IACS/2019-CS109A/tree/master/content/projects).