Ensemble Learning - Blending
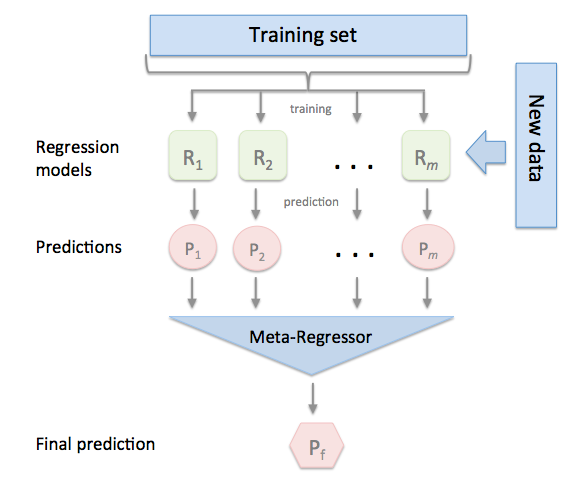
Introduction
Blending是基于Stacking的集成学习。 在Stacking集成学习的方法里面, 它分为两层,第一层里面多个模型(可以相同架构也可以不一样架构)直接从原来的训练集进行学习并预测输出。之后把第一层多个模型的输出作为第二层模型的输入对第二层模型进行训练。
Stacking的思路就好比上课时我上课迟到,我需要从其他同学的笔记里面进行学习归纳。这样子其他同学就相当于第一层的模型,直接从老师(数据)学习。而我就相当于第二层模型,从第一层模型的输出进行学习。
而在Stacking里面, 在第一层的模型是通过K-fold Cross validation 形式进行训练和预测。 而Blending的思路相对于把K-fold Cross validation换成Hold-Out。
以下是Stacking 步骤:
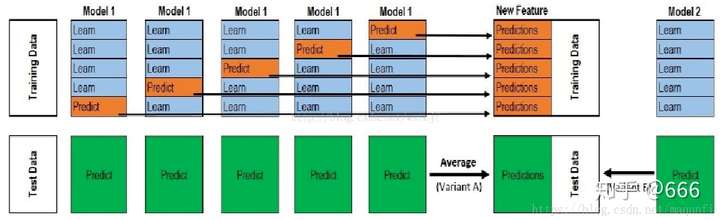 (图片来源: https://zhuanlan.zhihu.com/p/91659366)
(图片来源: https://zhuanlan.zhihu.com/p/91659366)
在Stacking里面, 它先对training data进行分割成K份然后用K-fold Cross Validation 进行模型的训练和对validation set进行预测。 第一层模型对alidation set的预测用作第二层模型的训练集。而在测试集里面,第一层所有的模型对test set的预测可以通过求均值的方式得到第二层模型的test set。 第二层模型的输出就是整个stacking 模型的输出。Stacking 由于用了 K-Fold CV 进行第一层模型训练,第一层模型输出的特征更加robust对数据的利用率也比较充分,但是就是训练慢。
Blending 步骤
- 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集
(val_set); - 创建第一层的多个模型,这些模型可以使同质的也可以是异质的;
- 使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict,
test_predict1; - 创建第二层的模型,使用val_predict作为训练集训练第二层的模型;
- 使用第二层训练好的模型对第二层测试集test_predict1进行预测,该结果为整个测试集的结果。
- Blending图解

Properties
优点
- 相对于Stacking, blending 用holdout更加简单
- 不需要太多理论分析
缺点
- 只用了holdout的数据集预测作为第二层的训练集,浪费数据
- 因为holdout数据用的少,输入第二层的数据很有可能导致模型overfitting
- 相对于Stacking, 因为用了Holdout而不是K-fold CV,不够robust
Source Code
Github 链接:
https://github.com/wenkangwei/Datawhale-Team-Learning/blob/main/Ensemble-Learning/Blending.ipynb
Reference
[1] https://zhuanlan.zhihu.com/p/91659366
[2] https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning