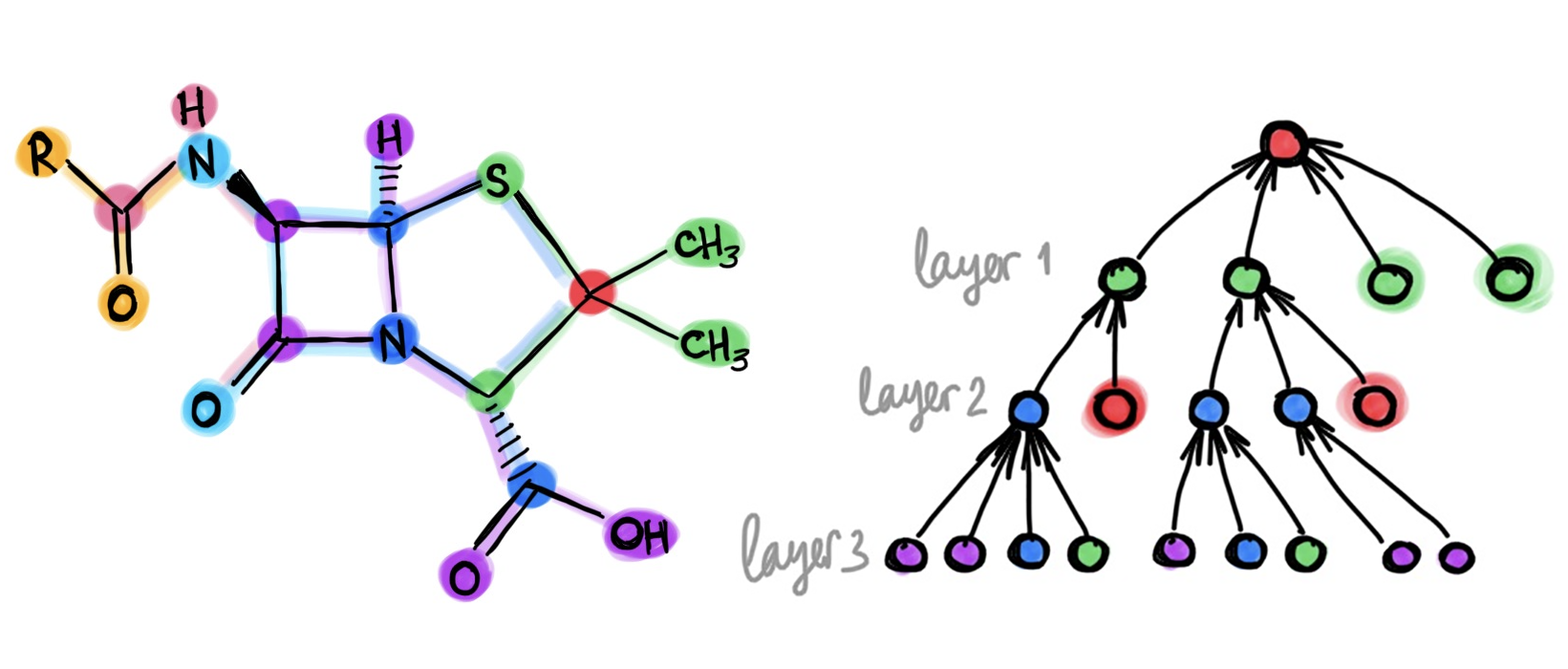
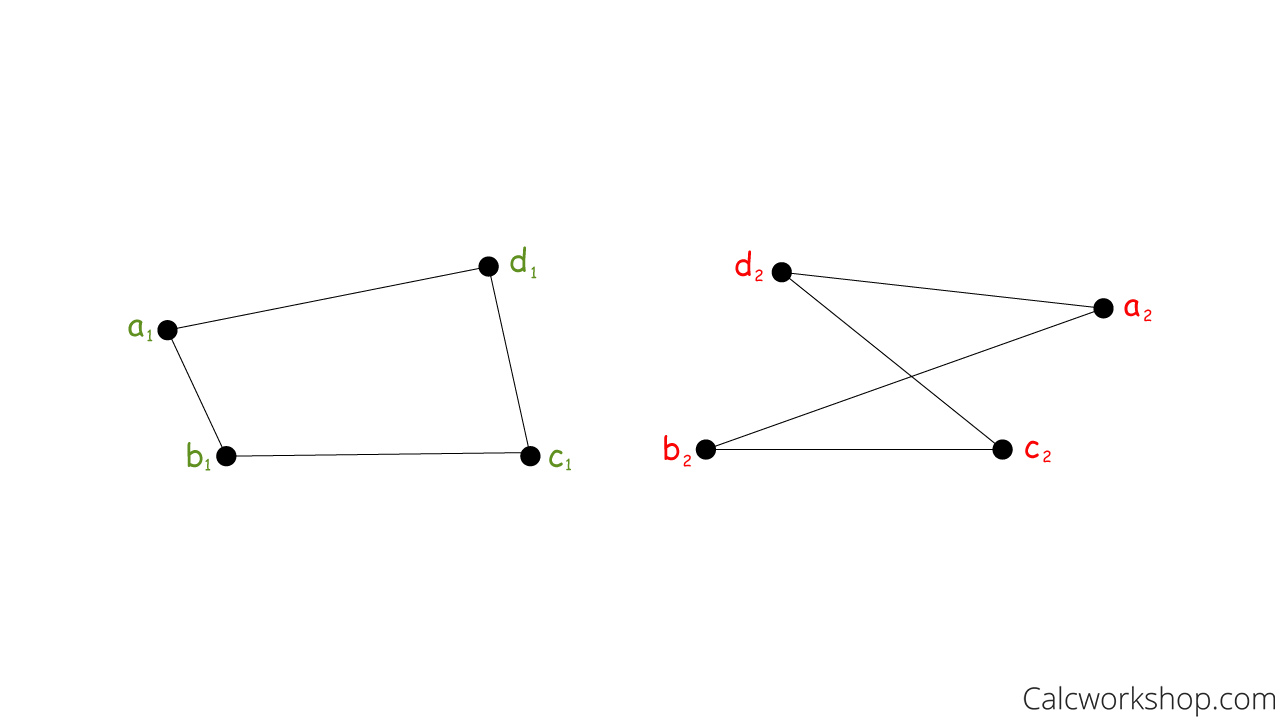
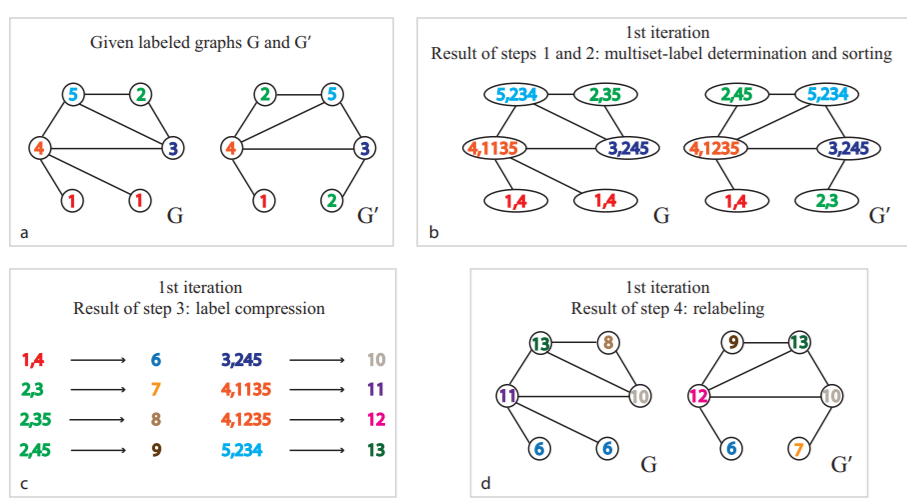
对于这几个问题,这篇博客会先回答什么是通构图,然后提及过去测试同构图和图的相似度的方法(Weisfeiler-Lehman Test and subtree kernels),之后会回答怎么用图神经网络GIN对graph representation进行学习。
2. What is Isomorphic Graph
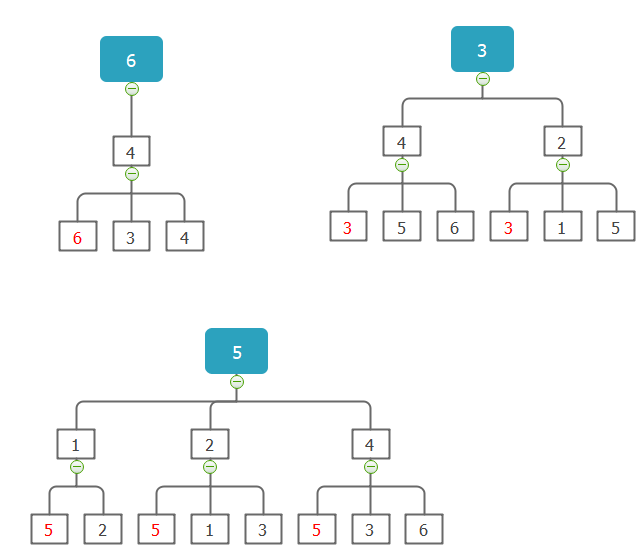
首先什么是同构图?根据WolframMathWorld的解释: Two graphs which contain the same number of graph vertices connected in the same way are said to be isomorphic. 如果两个图是同构就会满足以下特点(其中第2~4点意味两个图的连接方式一样):
for i, dim in enumerate(full_atom_feature_dims): emb = torch.nn.Embedding(dim, emb_dim) torch.nn.init.xavier_uniform_(emb.weight.data) self.atom_embedding_list.append(emb)
defforward(self, x): x_embedding = 0 for i in range(x.shape[1]): x_embedding += self.atom_embedding_list[i](x[:,i])
for i, dim in enumerate(full_bond_feature_dims): emb = torch.nn.Embedding(dim, emb_dim) torch.nn.init.xavier_uniform_(emb.weight.data) self.bond_embedding_list.append(emb)
defforward(self, edge_attr): bond_embedding = 0 for i in range(edge_attr.shape[1]): bond_embedding += self.bond_embedding_list[i](edge_attr[:,i])
import torch from torch import nn from torch_geometric.nn import global_add_pool, global_mean_pool, global_max_pool, GlobalAttention, Set2Set
import torch import torch.nn.functional as F
import torch from torch import nn from torch_geometric.nn import MessagePassing import torch.nn.functional as F from ogb.graphproppred.mol_encoder import AtomEncoder, BondEncoder
# computing input node embedding h_list = [self.atom_encoder(x)] # 先将类别型原子属性转化为原子表征 for layer in range(self.num_layers): h = self.convs[layer](h_list[layer], edge_index, edge_attr) h = self.batch_norms[layer](h) if layer == self.num_layers - 1: # remove relu for the last layer h = F.dropout(h, self.drop_ratio, training=self.training) else: h = F.dropout(F.relu(h), self.drop_ratio, training=self.training)
if self.residual: h += h_list[layer]
h_list.append(h)
# Different implementations of Jk-concat if self.JK == "last": node_representation = h_list[-1] elif self.JK == "sum": node_representation = 0 for layer in range(self.num_layers + 1): node_representation += h_list[layer]
return node_representation
classGINGraphPooling(nn.Module):
def__init__(self, num_tasks=1, num_layers=5, emb_dim=300, residual=False, drop_ratio=0, JK="last", graph_pooling="sum"): """GIN Graph Pooling Module Args: num_tasks (int, optional): number of labels to be predicted. Defaults to 1 (控制了图表征的维度,dimension of graph representation). num_layers (int, optional): number of GINConv layers. Defaults to 5. emb_dim (int, optional): dimension of node embedding. Defaults to 300. residual (bool, optional): adding residual connection or not. Defaults to False. drop_ratio (float, optional): dropout rate. Defaults to 0. JK (str, optional): 可选的值为"last"和"sum"。选"last",只取最后一层的结点的嵌入,选"sum"对各层的结点的嵌入求和。Defaults to "last". graph_pooling (str, optional): pooling method of node embedding. 可选的值为"sum","mean","max","attention"和"set2set"。 Defaults to "sum". Out: graph representation """ super(GINGraphPooling, self).__init__()
if self.training: return output else: # At inference time, relu is applied to output to ensure positivity # 因为预测目标的取值范围就在 (0, 50] 内 return torch.clamp(output, min=0, max=50)
defget_terminal_args(): parser = argparse.ArgumentParser(description='GNN baselines on ogbgmol* data with Pytorch Geometrics') parser.add_argument('--device', type=int, default=0, help='which gpu to use if any (default: 0)') parser.add_argument('--gnn', type=str, default='gin-virtual', help='GNN gin, gin-virtual, or gcn, or gcn-virtual (default: gin-virtual)') parser.add_argument('--drop_ratio', type=float, default=0.5, help='dropout ratio (default: 0.5)') parser.add_argument('--num_layer', type=int, default=5, help='number of GNN message passing layers (default: 5)') parser.add_argument('--emb_dim', type=int, default=300, help='dimensionality of hidden units in GNNs (default: 300)') parser.add_argument('--batch_size', type=int, default=32, help='input batch size for training (default: 32)') parser.add_argument('--epochs', type=int, default=100, help='number of epochs to train (default: 100)') parser.add_argument('--num_workers', type=int, default=0, help='number of workers (default: 0)') parser.add_argument('--dataset', type=str, default="ogbg-molhiv", help='dataset name (default: ogbg-molhiv)')
parser.add_argument('--feature', type=str, default="full", help='full feature or simple feature') parser.add_argument('--filename', type=str, default="", help='filename to output result (default: )') args = parser.parse_args() return args defmain(): # Training settings ## if obtain settings from terminal #args = get_terminal_args() args = Args() args.epochs = 5
device = torch.device("cuda:" + str(args.device)) if torch.cuda.is_available() else torch.device("cpu")
### automatic dataloading and splitting dataset = PygGraphPropPredDataset(name = args.dataset)
if args.feature == 'full': pass elif args.feature == 'simple': print('using simple feature') # only retain the top two node/edge features dataset.data.x = dataset.data.x[:,:2] dataset.data.edge_attr = dataset.data.edge_attr[:,:2]
split_idx = dataset.get_idx_split()
### automatic evaluator. takes dataset name as input evaluator = Evaluator(args.dataset)