Recommendation-System-EGES
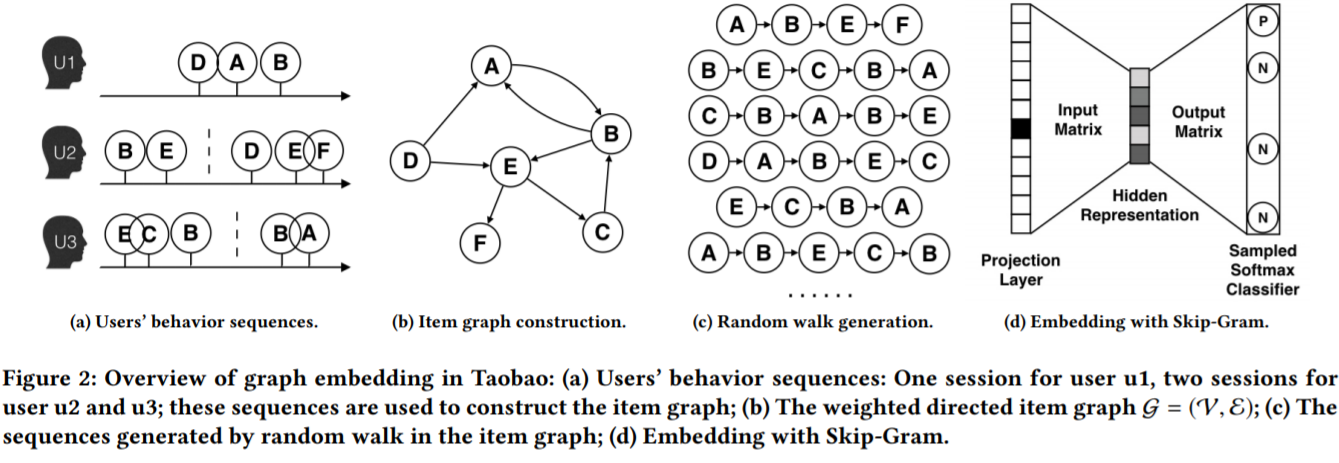
Introduction
这篇文章主要回顾和介绍2018年Alibaba在KDD里面提出的的EGES(Enhanced Graph Embedding with Side information) 模型。 这个模型主要是在DeepWalk 学习到embedding的基础上增添了其他item的补充信息(side inforamtion). 在介绍EGES之前,先介绍一下过去Item2Vec以及DeepWalk 学习item的embedding的特点以及一些不足。 之后再介绍EGES的思路和训练方法。
Item2Vec
Item2Vec可以看成是Word2Vec 在推荐系统里面的推广。 Word2Vec 假设的是 在一个长为T的窗口/句子里面有{w1, w2,… wT}个单词,然后计算第i个单词(central word)和第j个单词(context word)的同时出现的隔离. 而ItemVec则是不考虑窗口的概念,而是考虑在用户的一个浏览的历史里面浏览过的商品{w1, w2,… wT}, 把单词替换成item。它的objective function是
$$
\mathbf{L} = \frac{1}{K} \sum_ {i=1}^k\sum_ {j \neq i}^k log(w _i | w _j)
$$
Note: 在item2Vec的objective function里面它是计算每对商品之间的log的概率, 而word2Vec里面是计算给定的central word和其他context word之间的概率。这样看起来有点像是FM里面的特征两两交叉的操作
Item2Vec 的一些特点
- 广义上来讲, 只要能通过item的特征生成特征向量的方法都是item2Vec.
- Advantages:
- Item2Vec 是一个很广泛的概念,只要是序列数据都能够用来做embedding的学习,对item的embedding vector进行学习
- Disadvantages:
- 和Word2Vec 一样, Item2Vec只用了序列的数据,比如item的购买序列,但是却没有用到其他的特征信息,比如item和item, user和user, user和item之间的关联信息(Relationship data), item的tag是补充信息。
- 为了解决Item2Vec只能用序列信息的问题, GraphEmbedding提供了很好的解决方案。Graph Embedding里面充分利用了item的补充信息外还能学习item,user之间的关联信息。而DeepWalk 就是其中一种GraphEmbedding的方法
EGES
正如上面说的Item2Vec 只能用sequential data进行item的embedding vector学习,但是不能用到其他信息,比如item-item直接的关联,item的补充信息(categorical or numerical tags)。 而Graph Embedding的出现能够有效解决这个问题,之后也出现大量的graph embedding的学习方法。而 EGES (Enhanced Graph Embedding with Side Information) 就是其中之一。
Motivation
EGES (Enhanced Graph Embedding with Side Information) 是有Alibaba在2018年KDD里面提出来的基于DeepWalk的GraphEmbedding 方法结合了item补充信息而得到的模型。它先基于DeepWalk得到基本的GraphEmbedding 模型,然后逐步把Side Information添加到模型里面进行优化. 所以下面先解释DeepWalk, 之后再解释EGES模型
DeepWalk / Basic Graph Embedding (BGE)
DeepWalk 是在2014年KDD里面有Byran等人提出来的模型. Link:https://arxiv.org/pdf/1403.6652.pdf
在应用到Alibaba的推荐系统里面后它的基本流程如下:
收集用户的历史浏览数据
根据浏览数据搭建item之间的有向概率图。图里面每个节点代表一个item,而item之间的边是有向边,每条边都有对应的跳转概率。概率的计算公式如下, $P(v _j | v _i)$ 是从节点vi跳到vj 的概率,$M _{ij}$ 是从节点vi跳到vj的边的权重, 而 $N _{+} (v _i)$ 是节点vi的out-degree(出边)的节点的集合。 $\epsilon$是图中所有边的集合
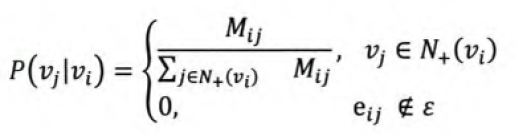
在概率图中用RandomWalk 随机游走采样多个物品序列
用这些序列放到Word2Vec里面训练得到Embedding,而其中的Objective/loss function 和Word2Vec的一样(如下形式), 都是minimize在center node已知的情况下context node的出现概率的negative log的值。
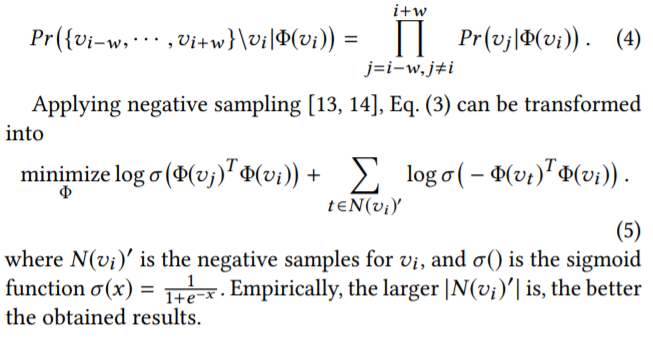
Graph Embedding with Side information (BES)
虽然DeepWalk学习到的embedding能够学习到Collabortive Filtering学不到的行为序列的关系,但是它依然有以下问题:
- 不能解决冷启动问题,面对新进来的item, item的graph是没有新进来的item信息
- item的其他side information比如 标签信息等并没有充分利用
所以这里做的一个改进就是把side information也做embedding。得到item embedding以及side information的embedding。 其中$W _v^0$ 是原来学习到的item v 的embedding, $W _v^s$是第s个的side information的embedding。如果side information的embedding有n个,那么这个item v的embedding个数总共有n+1个,之后item v的所有embedding通过average pooling的方法进行信息融合得到对应item的embedding, 即$H _v$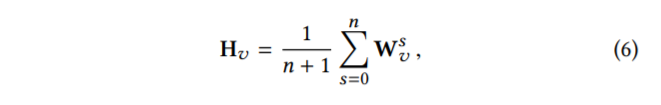
Enhanced Graph Embedding with Side information (EBES)
那么问题又来了, 虽然GES能够通过side information解决冷启动的问题,但是每个用户对一个item的喜欢的信息是有倾向性的,比如一个用户喜欢一台手机是因为它是IPhone, 另一个用户喜欢一台手机是因为它是续航能力强,那么用户对这些特征的倾向性也应该反映到对embedding的倾向性上面,如对”Iphone” 或”续航能力强”这个tag的embedding的权重应该提高。 因此它对每个embedding应该加上一个权重。于是, item的embedding的形式被调整成下面形式
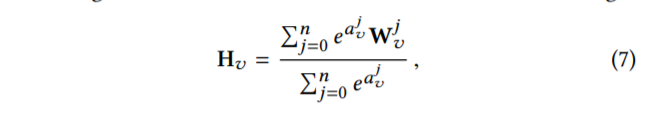
其中:
- $a _v^j$ 是第v个item第j个embedding的权重值,由于要保证这个weight是大于0,于是用来exponent 作为底数
- $H _v$是对第v个item所有embedding的weighted sum
在更新了Embedding的公式之后,EGES的embedding再乘上一个output matrix然后做softmax进行概率的预测,这一点和Word2Vec 一样。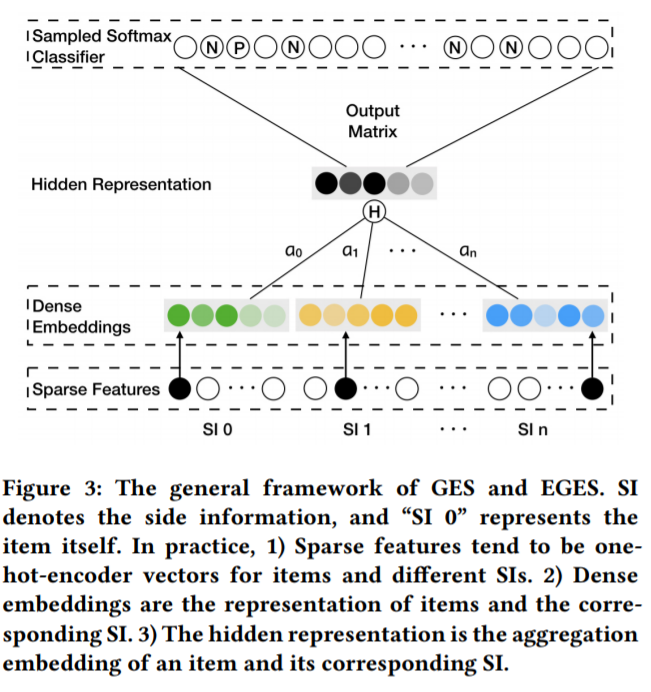
loss用的是binary cross entropy. $Z _u$ 是context node u的embedding的信息,$H _v$是center node的embedding信息。这里的context node在原文中是通过negative sampling方法来采样负样本的节点,和Word2Vec一样。
Experiment
原文里面用的评估方式也是传统的线下AUC和线上A/B CTR testing的评估。这个就不多说了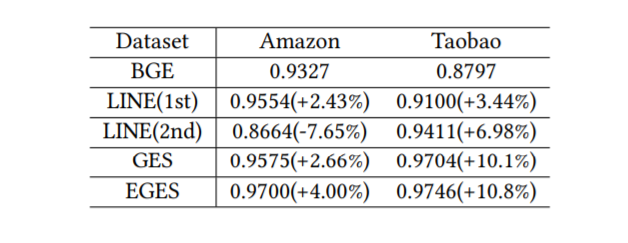
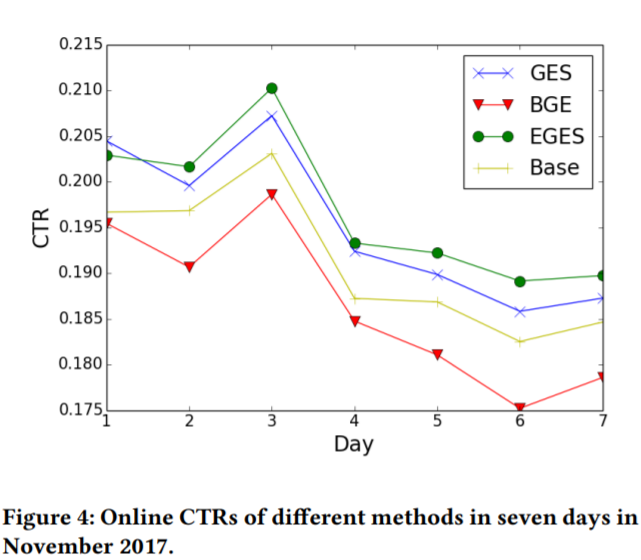
Opinions
这里对上面一些算法的思考:
- 在DeepWalk 生成概率图来重新采样时,这个跳转的概率应该是要逼近实际的数据中两个item之间的有向关系,这种情况下,一般是要数据越大越好,才能逼近真实的关系
- Deepwalk 里面的图只能计算已经知道的item之间的关系,对应新进来的item是始终有冷启动的问题。 而面对这个问题EGES是通过引入side information的embedding进行新的item信息填充来解决一开始新item没有embedding的情况
- 个人认为EGES创新性一般,主要还是在原因的deepwalk模型里面引入其他信息的embedding,而其他步骤基本上和Word2Vec一样。 不过这个其实能够解决冷启动问题而且也一定程度上提高了CTR的表现,算是比较实用的模型
Source Code
这里基于SparrowRecSys 开源推荐系统的github代码自己重新写了一遍 DeepWalk的graph embedding的计算. 我自己在弄的推荐系统的github:https://github.com/wenkangwei/RecSys
1 | %%writefile embedding.py |
Reference
[1] Alibaba-EGES: https://arxiv.org/pdf/1803.02349v2.pdf
[2] DeepWalk: https://arxiv.org/pdf/1403.6652.pdf
[3] SparrowRecSys: https://time.geekbang.org/column/article/296932
[4] 推荐算法大佬的github: https://github.com/shenweichen/GraphEmbedding
[5] DeepWalk的原文: http://www.perozzi.net/publications/14_kdd_deepwalk.pdf