Recommendation-System-9-Swing
Motivation
在推荐系统里面处理上亿级别的用户是一个challenging的问题,特别是在捕捉用户的实时行为,比如click, add bag等行为。另外,过去的协调滤波CF的方法里面有以下问题:
- Accuracy: 只考虑到user-item之间的关系,而忽略了用户内在的行为之间的关系,从而导致accuracy受限制
- Sparity:用户购买行为的数据是非常稀疏,在大量的用户和商品里面, 可能被购买的商品就只有那么几个,从而导致对用户的购买行为捕捉困难度增加
- Direction: 在Co-purchase联合购买行为里面,是存在方向性的,有可能购买A商品会也购买B商品,但是反过来的行为不一定频繁
- Scalability: 在上亿级别用户里面用户数和商品数是在不断增长的,模型的可延展性scalability也是一个重要的问题
而Swing是 阿里淘宝提出的一个计算item之间相似度的模型,它主要把用户,商品之间的二分图bi-graph进行搭建,对user-item-user的关联行为考虑进来从而进一步利用用户的内在行为之间的关联。
How does Swing work
- Assumption
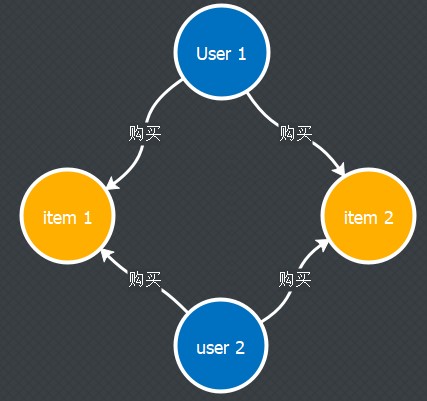
在用户的点击行为里面是经常充满噪声的,比如用户误点或者随机点击的行为,从而导致这些行为可行度不大。因此, Swing这里提出了一个assumption: 如果一个用户同时点击两个item i和j那么这个行为有可能是随机的。 但是如果同时有两个user都同时点击item i和j,那么item i和j的关系就更加可行
那么 user和item之间的关系图就变成下面的bi-graph图片
- Formula
Swing的计算公式如下:

它计算item i和j之间的相似度时,先通过找出购买过item i 的user集合Ui 以及购买过item j 的user 集合Uj, 之后找到Ui, Uj之间的user交集。 在都购买过i,j商品的user里面再看看这些user之间的购买的商品的交集数的倒数。 如果这些用户是因为经常购买商品从而同时购买item i和就的话,导致交集很大,那么相似度就会下降,也就是这些用户的行为不可信。
而alpha是一个smoothing factor。
另外因为active user购买的商品数目一般很大,容易导致Iu 和Iv的交集很大,使score偏小 存在bias,这里引入了一个penalty的weight对score进行调整

Properties
Advantages
- 计算简单而且能够并行计算,适用于召回层
- 无序考虑购买item的顺序
- 结合图结构,item之间的关联可靠性强
Disadvantages
- 计算慢,Time Complexity O(T x N^2 x M), T: # of item, N: average degree of item, M: the average node degree of a user
When to Use
- 推荐召回层里面可以使用,无需使用太多特征,只需user, item购买列表
Reference
[1] https://arxiv.org/pdf/2010.05525.pdf