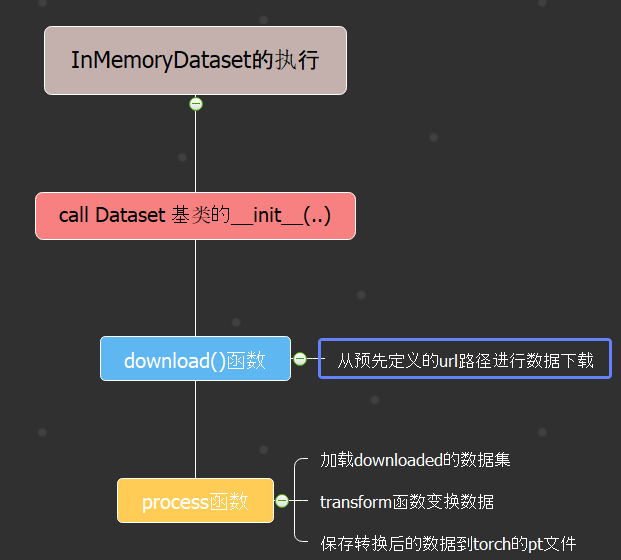
先来看看 InMemoryDataset的官方解释: class InMemoryDataset(root: Optional[str] = None, transform: Optional[Callable] = None, pre_transform: Optional[Callable] = None, pre_filter: Optional[Callable] = None) Dataset base class for creating graph datasets which fit completely into CPU memory. See here for the accompanying tutorial. PARAMETERS
root (string, optional) – 用于存放数据集的根目录路径(默认为None)
transform (callable, optional) – A function/transform that takes in an torch_geometric.data.Data object and returns a transformed version.
pre_transform (callable, optional) – A function/transform that takes in an torch_geometric.data.Data object and returns a transformed version. The data object will be transformed before being saved to disk. (default: None)
pre_filter (callable, optional) – A function that takes in an torch_geometric.data.Data object and returns a boolean value, indicating whether the data object should be included in the final dataset. (default: None)
import torch from torch_geometric.data import InMemoryDataset, download_url from torch_geometric.io import read_planetoid_data
classMyDatasetMem(InMemoryDataset): def__init__(self, root, url =None, raw_file_names= None, dataset_name="citeseer", version="ind", transform=None, pre_transform=None): r"""Dataset base class for creating graph datasets which fit completely into CPU memory. See `here <https://pytorch-geometric.readthedocs.io/en/latest/notes/ Args: root (string, optional): Root directory where the dataset should be saved. (default: :obj:`None`) transform (callable, optional): A function/transform that takes in an :obj:`torch_geometric.data.Data` object and returns a transformed version. The data object will be transformed before every access. (default: :obj:`None`) pre_transform (callable, optional): A function/transform that takes in an :obj:`torch_geometric.data.Data` object and returns a transformed version. The data object will be transformed before being saved to disk. (default: :obj:`None`) pre_filter (callable, optional): A function that takes in an :obj:`torch_geometric.data.Data` object and returns a boolean value, indicating whether the data object should be included in the final dataset. (default: :obj:`None`) 自定义参数: url: url to data source website to download dataset raw_file_names: raw_file_name to download dataset_name: name of dataset to download, like PudMed, Cora, Citeseer version: "ind": inductive version of dataset (predict on unseen node) "trans": transductive version of dataset (train and predict on all visited node) """ self.dataset_name = dataset_name self.root = root if url != None: self.url = url else: self.url = "https://github.com/kimiyoung/planetoid/raw/master/data" if version == "ind"or version == "trans": self.version = version else: print(f"No such version: {version}") self.version = "" assertFalse if raw_file_names!=None: self.raw_files = raw_file_names else: names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index'] self.raw_files = [f'{self.version}.{self.dataset_name.lower()}.{name}'for name in names] # call the initialize function from InMemoryDataset to # download and process the dataset and save the processed dataset to processed_data.pt file super(MyDatasetMem, self).__init__(root, transform, pre_transform) print("Processed data path: ",self.processed_paths[0]) #load the saved processed dataset self.data, self.slices = torch.load(self.processed_paths[0]) @property defraw_dir(self): """ return directory that stores the raw data files """ return osp.join(self.root, 'raw') @property defraw_file_names(self): r"""The name of the files to find in the :obj:`self.raw_dir` folder in order to skip the download.""" return self.raw_files
@property defprocessed_file_names(self): r"""The name of the files to find in the :obj:`self.processed_dir` folder in order to skip the processing.""" # Note: processed data is stored into torch.pt file returnf'{self.dataset_name}_processed_data.pt' defdownload(self): """ download data from url based on file names to raw directory """ for file in self.raw_file_names: download_url('{}/{}'.format(self.url, file), self.raw_dir) defprocess(self): """ Load dataset from local directory """ data = read_planetoid_data(self.raw_dir, self.dataset_name.lower()) data = data if self.pre_transform isNoneelse self.pre_transform(data) torch.save(self.collate([data]), self.processed_paths[0]) definfo(data,): print("Number of classes: ",data.num_classes) print("Number of nodes: ",data[0].num_nodes) print("Number of edges: ",data[0].num_edges) print("Number of features: ",data[0].num_features)
Processing...
Done!
Processed data path: dataset/MyDatasetMed/processed/citeseer_processed_data.pt
Number of classes: 6
Number of nodes: 3327
Number of edges: 9104
Number of features: 3703
Processing...
Done!
Processed data path: dataset/MyDatasetMed/processed/Cora_processed_data.pt
Number of classes: 7
Number of nodes: 2708
Number of edges: 10556
Number of features: 1433
Processing...
Done!
Processed data path: dataset/MyDatasetMed/processed/pubmed_processed_data.pt
Number of classes: 3
Number of nodes: 19717
Number of edges: 88648
Number of features: 500
import torch from torch.nn import functional as F from torch.nn import LeakyReLU, Dropout, BCEWithLogitsLoss, Linear from torch_geometric.datasets import Planetoid from torch_geometric import transforms as T from torch_geometric.utils import train_test_split_edges, negative_sampling from torch_geometric.nn import GCNConv, GATConv, Sequential
from sklearn.metrics import roc_auc_score from matplotlib import pyplot as plt import seaborn as sns import numpy as np
# Define Mynet classMyNet(torch.nn.Module): def__init__(self, in_channels, out_channels,hidden_channels_ls= [128,128], dropout_rate=0.5,random_seed=None): super(MyNet, self).__init__() torch.manual_seed(random_seed) hidden_channels_ls = [in_channels] + hidden_channels_ls self.conv_ls =[] # Task 1: 使用PyG中的不同的网络层去代替GCNConv,以及不同的层数和不同的out_channels,来实现节点分类任务。 for i in range(len(hidden_channels_ls)-1): hd_in_channel = hidden_channels_ls[i] hd_out_channel = hidden_channels_ls[i+1] # input: x and edge_index output: x self.conv_ls.append( (GATConv(hd_in_channel, hd_out_channel), 'x, edge_index -> x') ) self.conv_ls.append( (LeakyReLU(negative_slope=0.5)) ) self.conv_ls.append( (Dropout(dropout_rate)) ) # Task 2: 在边预测任务中,尝试用torch_geometric.nn.Sequential容器构造图神经网络。 self.conv_seq = Sequential('x, edge_index', self.conv_ls) # classifier self.dropout = Dropout( dropout_rate) self.linear = Linear(hidden_channels_ls[-1], out_channels) defencode(self, x, edge_index): x = self.conv_seq(x, edge_index) x = self.dropout(x) x = self.linear(x) return x
defdecode(self, z, pos_edge_index, neg_edge_index): edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1) # multiply source and target node embedding and sum up all embedding feature values along column # It does dot product operation here to compute similarity between source and target nodes return (z[edge_index[0]] * z[edge_index[1]]).sum(dim=-1)
defdecode_all(self, z): prob_adj = z @ z.t() return (prob_adj > 0).nonzero(as_tuple=False).t() defget_link_labels(pos_edge_index, neg_edge_index): """ Concatenate positive edge and sampled negative edge into a tensor and mark them as 1 or 0 label """ num_links = pos_edge_index.size(1) + neg_edge_index.size(1) link_labels = torch.zeros(num_links, dtype=torch.float) link_labels[:pos_edge_index.size(1)] = 1. return link_labels
z = model.encode(data.x, data.train_pos_edge_index)
results = [] for prefix in ['val', 'test']: pos_edge_index = data[f'{prefix}_pos_edge_index'].to(device) neg_edge_index = data[f'{prefix}_neg_edge_index'].to(device) # make prediction on link from model link_logits = model.decode(z, pos_edge_index, neg_edge_index).to(device) # convert prediction values to possibility link_probs = link_logits.sigmoid() # compute loss for link link_labels = get_link_labels(pos_edge_index, neg_edge_index) results.append(roc_auc_score(link_labels.cpu(), link_probs.cpu())) return results
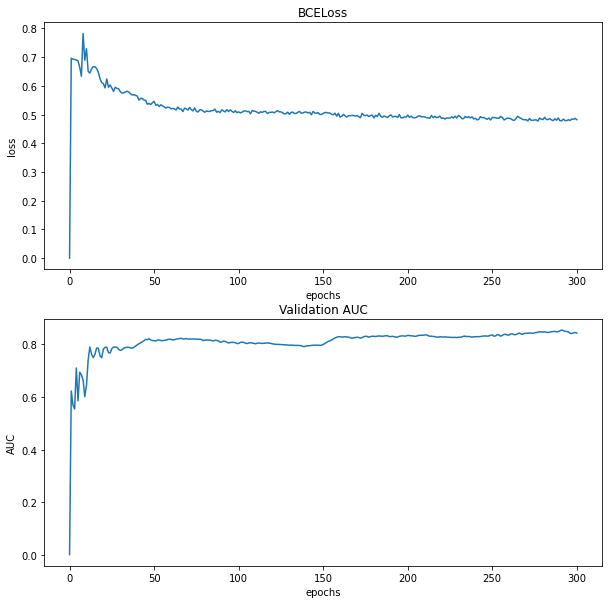
defmain(dataset): # load self-defined dataset: 这里调用之前学的 自定义的 InMemoryDataset epochs = 300 random_seed = 2021 np.random.RandomState(random_seed) torch.manual_seed(random_seed) data = dataset[0] data.train_mask = data.val_mask = data.test_mask = data.y = None device = torch.device("cuda"if torch.cuda.is_available() else"cpu") print(f"Using device: {device}") print() data = train_test_split_edges(data,val_ratio = 0.05, test_ratio = 0.1) print("Data info:") print(data) data.to(device) # define loss, optimizer and model: 这里调用选取要用的loss,模型,优化器等配置 model = MyNet( in_channels = data.num_features, out_channels = 64, hidden_channels_ls= [128,128], dropout_rate=0.5, random_seed= random_seed).to(device) loss_fn = BCEWithLogitsLoss() optimizer = torch.optim.Adam(model.parameters(), lr = 1e-2) # train model: 模型训练 best_val_auc = test_auc = 0 loss_ls = [0] val_auc_ls = [0] for epoch in range(1, epochs+1): loss = train(data, model, optimizer, loss_fn, device) loss_ls.append(loss.detach().item()) # validation and test val_auc, tmp_test_auc = test(data, model,device) #val_auc =val_auc.detach() #tmp_test_auc = tmp_test_auc.detach() val_auc_ls.append(val_auc) if best_val_auc < val_auc: best_val_auc = val_auc test_auc = tmp_test_auc if epoch%20 ==0: print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_auc:.4f}, ' f'Test: {test_auc:.4f}') # Make final prediction on all links z = model.encode(data.x, data.train_pos_edge_index) final_edge_index = model.decode_all(z) torch.cuda.empty_cache() t =[0] + [i+1for i in range(epochs)] fig, ax = plt.subplots(2, figsize=(10,10)) sns.lineplot(t, loss_ls, ax= ax[0]) sns.lineplot(t, val_auc_ls, ax= ax[1]) ax[0].set_xlabel("epochs") ax[1].set_xlabel("epochs") ax[0].set_ylabel("loss") ax[1].set_ylabel("AUC") ax[0].set_title("BCELoss") ax[1].set_title("Validation AUC") plt.show()